Over at Daring Fireball, John Gruber makes a passing observation about the Apple Sports app:
I’ve got some gripes about certain specific aspects of Apple Sports. Like, where does one even start to explain how much is wrong with their zero-sum visualization of team stats? Has anyone ever even seen a presentation like that before? Anyone?
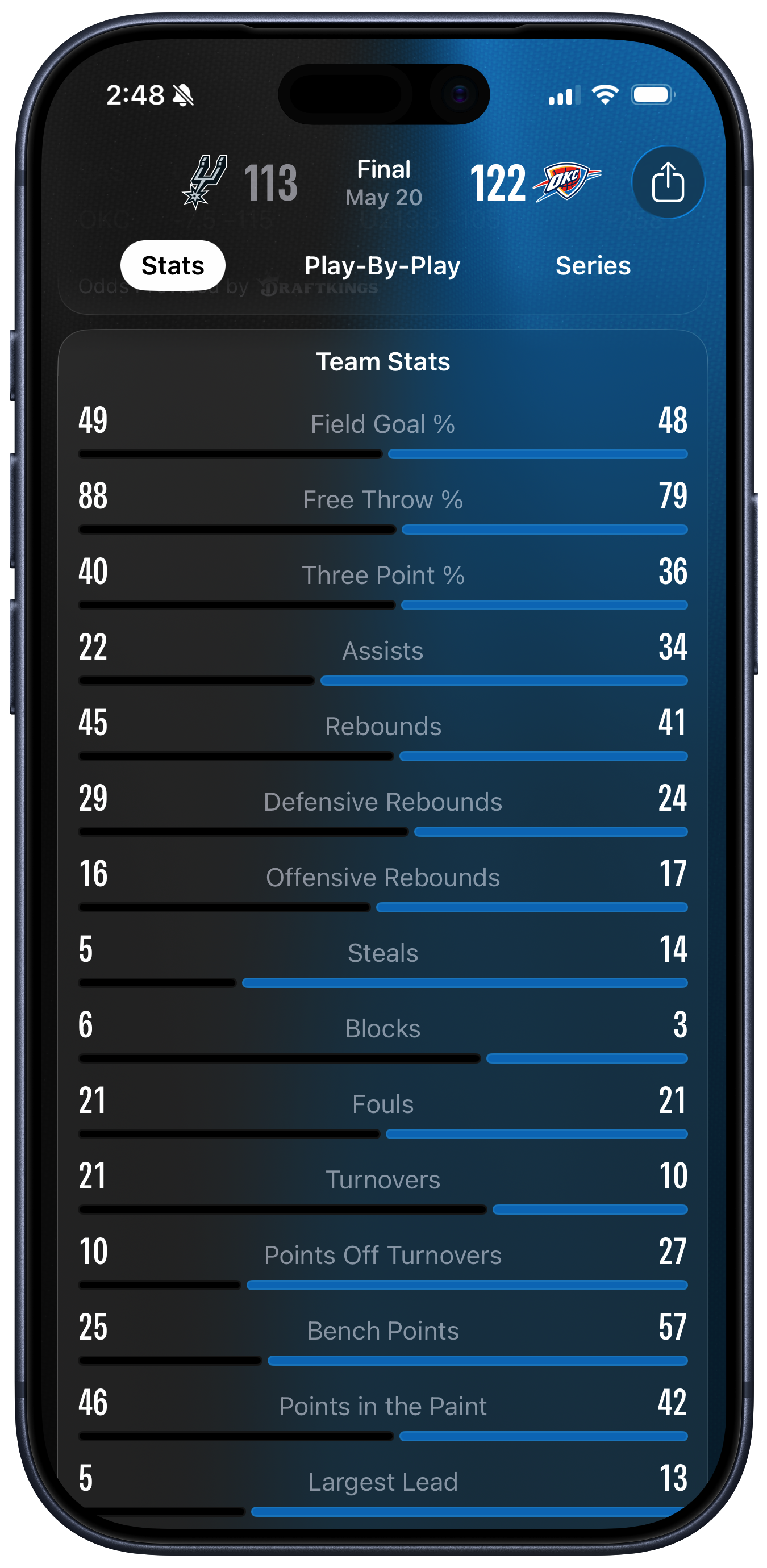
That “Anyone” link lands over here. Hi everyone! The team stats image is quite confusing. It’s a summary of a game between the San Antonio Spurs and the Oklahoma City Thunder. I don’t know much about basketball, but I do know a bit about data visualization and in a pleasing coincidence my former student Josh Fink is the A-VP of Basketball Data Science for the Spurs. Here is the image that John objected to: ❧ Continue reading…
Snow in Inwood, New York. Photograph by the author.
Recently I’ve been looking at hourly ridership data from the New York City Subway. Last time we learned that people go to work in the morning and come home in the evening, for example. (All together now: “Only in New York, baby!”) Today we’ll learn that bad weather makes people stay at home. Except, sometimes it doesn’t. ❧ Continue reading…
Pie charts are bad, as
any fule kno. We’re not as good at judging relative differences between angles
and areas as we are at judging relative differences in lengths on a common
baseline. This is especially true when we have more than two things to compare
at the same time. So, as a rule, you shouldn’t use them. You should figure out
some other way of viewing your data instead. On the other hand, I just made 424
animated pie charts because if you’re going to break a rule you should break
it good and hard. ❧ Continue reading…
The five boroughs of New York City can be informally or formally carved up into many different pieces, depending on what it is that you’re doing. As part of an ongoing project, I recently made an R package, nycmaps, that lets you draw maps of some of these geographies. Things being what they are, these spatial units don’t necessarily overlap in compatible ways. City, State, and Congressional Districts, School Districts, Police Precincts, Fire Companies, Election Precincts, Municipal Court Districts, Zip Codes … there are loads of them. Some of them are quite straightforward; others patiently lie in wait to trap unwary analysts (I’m looking at you, Zip Codes / ZCTAs). ❧ Continue reading…
After the parking signs last time, here is a subway sign.
A borough-specific sign to display
Here’s a direct link to the PNG and the PDF. Once again, put it onna stick and exercise the constitutional rights to freedom of expression, speech, and assembly enjoyed by everyone in the United States. ❧ Continue reading…
{kind=link}

