Clustering Pundits
For the past view years, Jason Snell at Six Colors has conducted a survey of people who write about Apple. He asks a series of questions about the company and its products and presents a report of people’s answers. This year’s report has all the details for those interested.
I’m a subscriber to Six Colors (it’s well worth it if you like that sort of thing). In the course of chatting about the report and its graphs in the member Slack, Jason kindly shared an anonymized version of the survey data with me. I made a few quick graphs looking at the distribution of responses, which he shared on his site a few days ago. It includes a … let’s say … quite relaxed overview of how to interpret a PCA biplot.
Here are a few bonus figures and a little information about the code to make them. As usual I’m working in R, ggplot2 and the tidyverse generally.
The data look like this:
|
|
We have an anonymous respondent id, and answer scores for each of twelve questions. Respondents could score Apple from 1 (worst) to 5 (highest) on each topic, whole numbers only. If a respondent chose not to answer, we see an NA indicating a missing value.
The main thing I was interested in was getting a sense of the variation across topics and respondents. To get a sense of the range of variation across questions, I did what I recommended in an earlier post on comparing distributions. That is, use a small-multiple graph to show a histogram for each of the twelve questions, while also showing the overall distribution of opinion in the background of each panel. So here, the distribution in gray is the same in every panel and is based on the overall average score awarded by each respondent. In purple is the distribution of answers for each particular question.
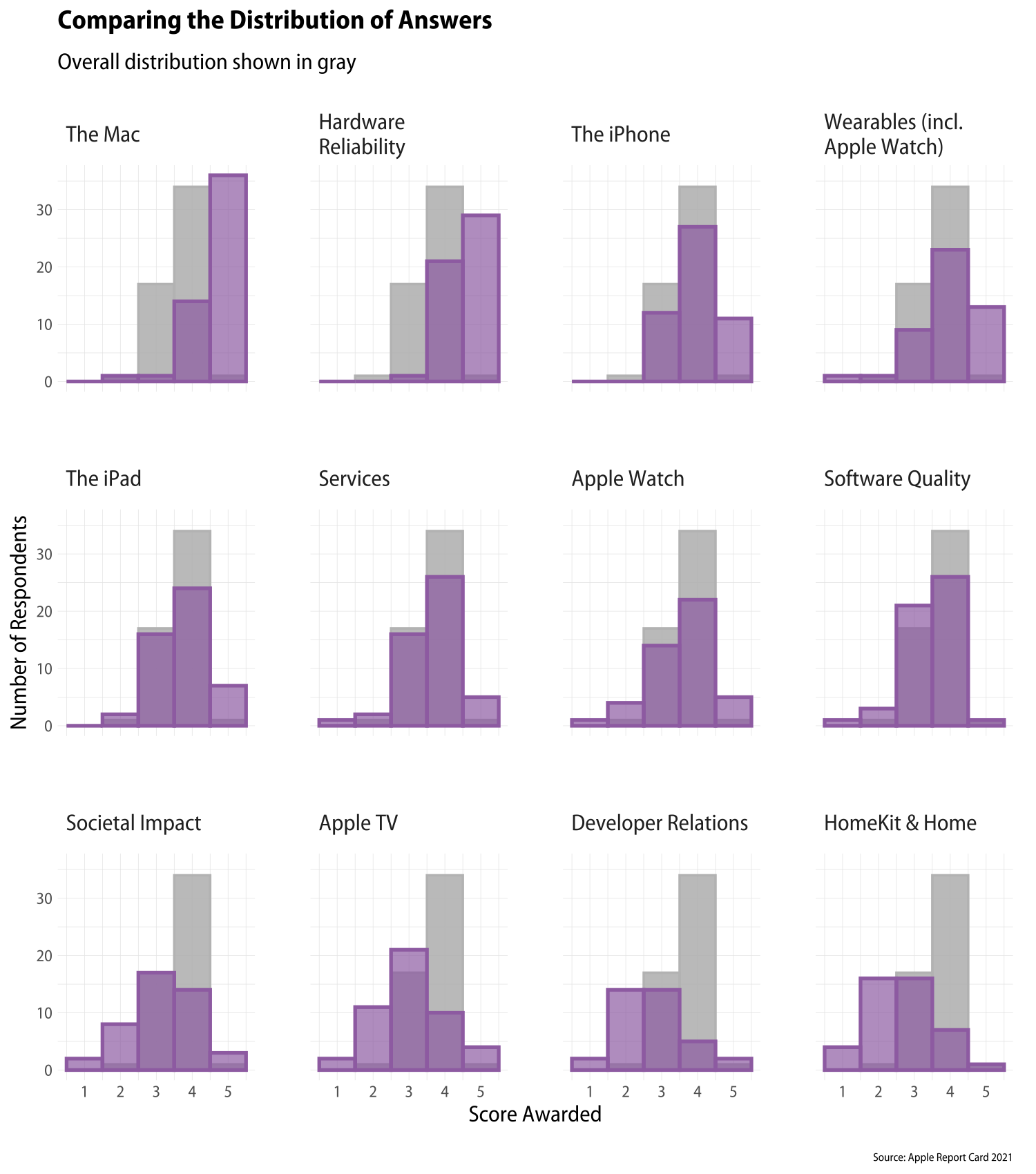
Comparing the distribution of answers.
This way we can look across the panels while also having a sort of anchor point inside each one to bring out how the particular topic differs from people’s overall impression. We also order the panels from highest to lowest average score, so that reading from top left to bottom right shows a pattern of increasing ambivalence and dissatisfaction.
Next, what about variation across respondents? There are at least two sources of variability here. First, people have different opinions. Second, net of their opinions some people are just tougher graders than others. We could draw a similar graph to the one above with a panel for each respondent, but with more than fifty of them things get a little crowded. A second possibility is to put each respondent on the y-axis (again ranked from most to least generous on average) and show each of their scores on the x-axis. Here’s what that looks like.
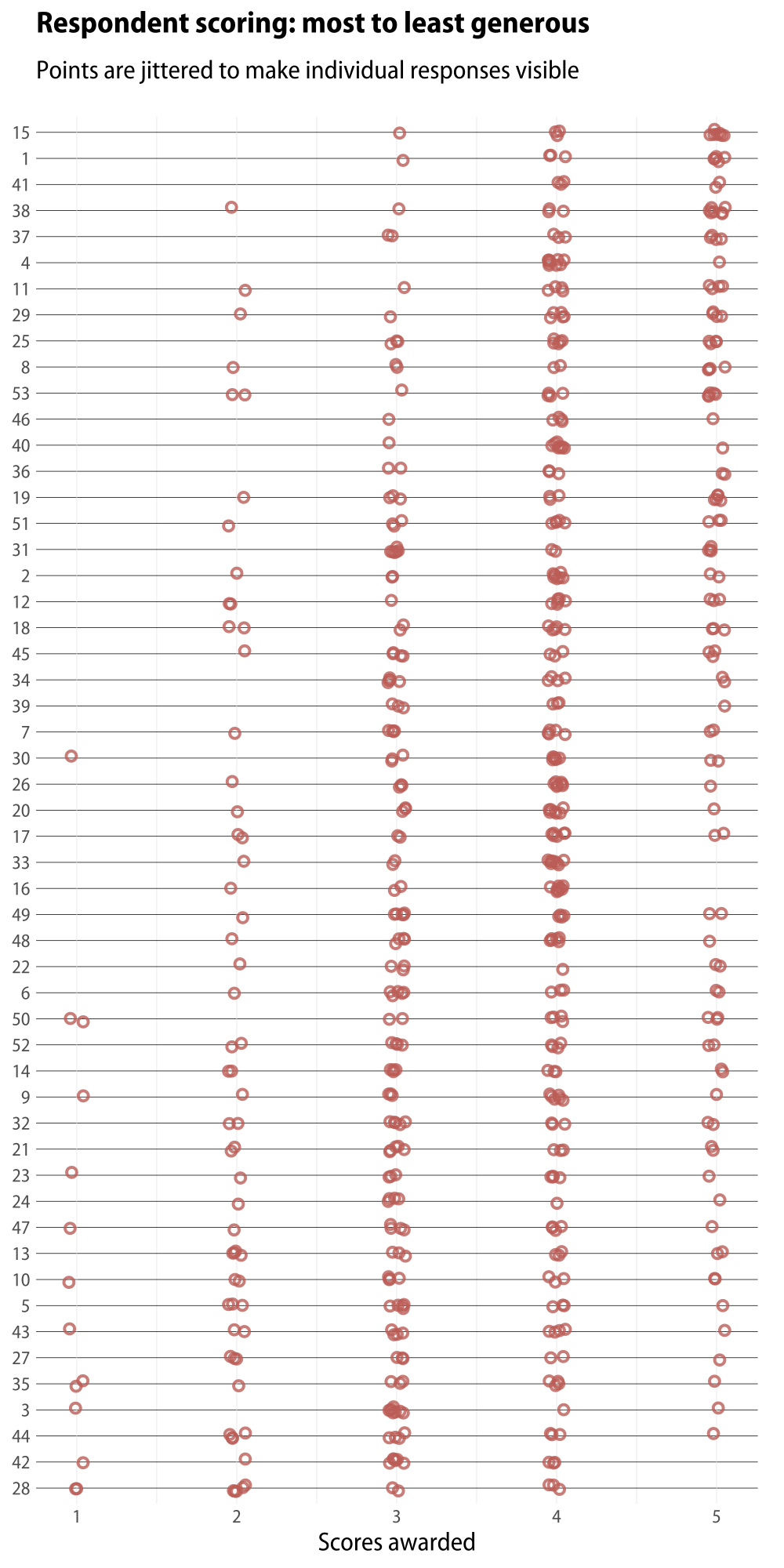
The distribution of answers by respondent.
Putting your categories (in this case, the respondents) on the y-axis is a very useful way to compare a lot of cases. In effect the graph takes on some of the virtues of a table, and in general it’s easier to extend tabular layouts vertically than it is horizontally. (You also don’t have to mess around with rotating labels or things like that.) There are some trade-offs. The main one is that respondents can only pick integer values for their scores, which means everything clumps together. Here I jitter the values just a little to show there are a bunch of them sitting on top of one another. Other ways to do this would be to draw circles proportional to the number of answers at any particular value.
Things get a little more fun when we try to jointly visualize the respondents and their answers. In the post at Six Colors I did a PCA biplot, which tries to reduce the space of twelve questions a series of orthogonal dimensions that we can graph, ideally with the first couple of dimensions accounting for most of the variance in the answers. An alternative (and similarly inductive) approach is to think in terms of clusters of both questions and respondents. The intuition here is that there are different sorts or categories of topic (and also kinds of respondent) and we can somehow cluster them together. That is, we can come up with some measure of how far away respondents are from one another in the multidimensional space of questions. Conventionally, the most straightforward metric is Euclidean distance, but there are many others. With a distance measure in hand, we can then use some method of grouping the points (here, survey respondents) into clusters. Again, there are very many options for how to do this. Generally speaking these are inductive methods where the analyst generally chooses both the clustering method and the cutoff for number of groups. The result is a lot of interpretive freedom (you’re encouraged to think about whether the groups found by the methods make sense), combined with a certain amount of arbitrariness (this method? this grouping? this value for k?), and, often, a kind of inability to stop futzing with the results in an effort to see if you can make the groupings a bit more plausible or parsimonious or what have you. I once heard my PhD advisor, Paul DiMaggio, remark that cluster analysis was like Afghanistan, in the sense that people knew how to get in to it but not how to get out.
At any rate, I hierarchically clustered the respondents on the basis of Euclidean distance and Ward’s D. This produces a dendrogram, a tree diagram where we can see each respondent put next to their most similar peer, while also seeing how everyone might be agglomerated in to larger and larger groups. It looks like this:
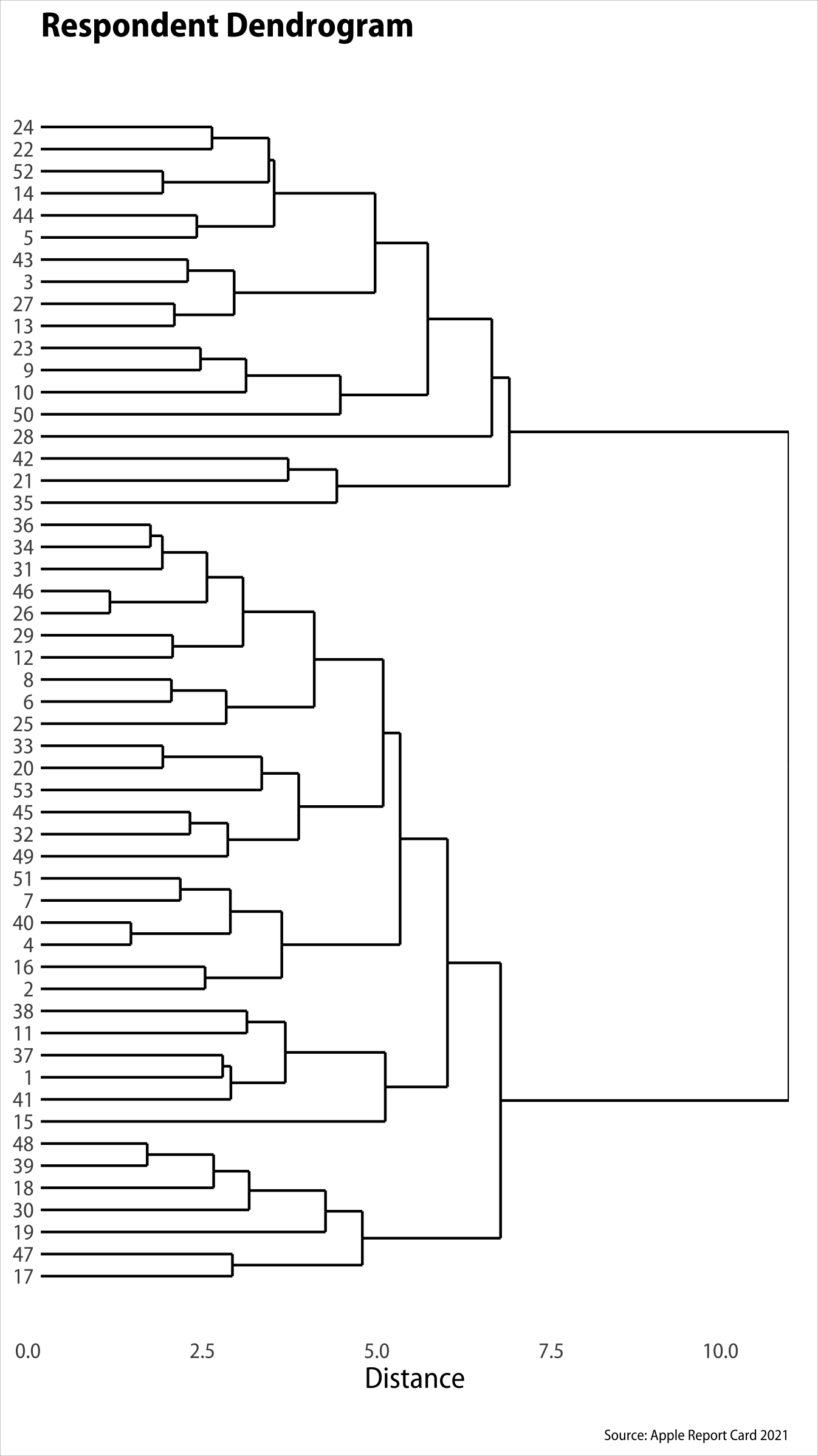
Dendrogram
At the largest level of agglomeration the tree is split into two main branches, with several more splits down the line until we get to the individuals. You can see one respondent, #28, quickly ends up in a branch by themselves. This respondent has by far the most negative pattern of responses in the survey.
Can we say anything about the meaning of the groups that our method has picked out? Possibly! The fun here, naturally, is that I don’t know who anyone in particular is, even though I do know the names of the respondents as a group. One thing we can do with this clustering result is to use it to permute the rows of our data. So we shuffle the rows to make the similar respondents be close to one another, as per the dendrogram. We can also cluster the twelve questions in the same way, and permute the columns of the data in the same fashion. Once we’ve done that, we can make a tile-map of the individual answers. Each particular answer from a respondent is a square with a color indicating its numerical value. Let’s make it a temperature-like scale with the midpoint as the average score (about 3.6). Better scores are more red, worse scores are more blue. The midpoint is white. I’ll put the dendrogram on the side to you can see how the rows are permuted. The respondent numbers are on the right. Here’s what that looks like:
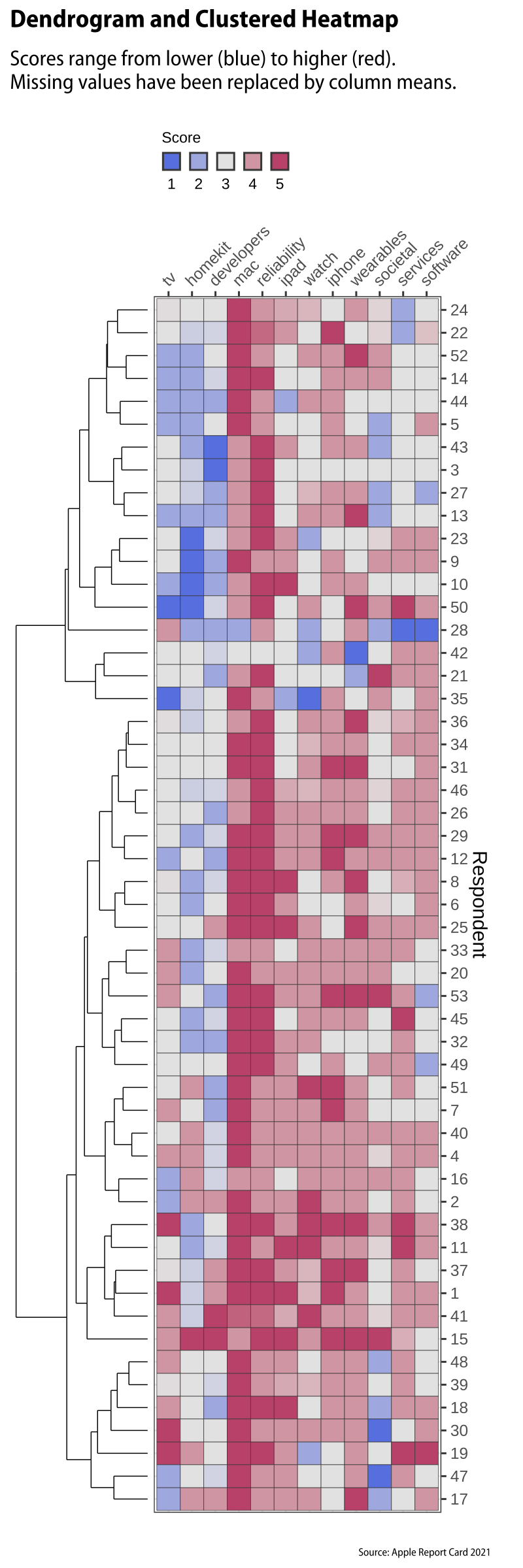
Cluster dendrogram and heatmap
We can see a reasonable amount of structure here. The reddest columns are the scores for the Mac, almost uniformly positive, along with the question on hardware reliability. These form a kind of division. To the right are questions where views are mostly positive to neutral. To the left are topics (TV, Homekit, Developers) where views are mostly neutral to negative. Down the rows, meanwhile, we can see some evidence of different kinds of respondent in the pool. At the bottom are people who are generally happy with most of what Apple is doing and who are neutral or only slightly negative on the Development, TV, and Homekit questions. At the top are respondents who are both less pleased on average and particularly annoyed with the TV, Homekit, and/or the Developer topics.
I wouldn’t say there’s a tremendous amount of variation. This is partly because of the way the survey is structured, and the fact that most people are broadly lukewarm-to-favorable on most topics. (With the exception of Respondent #28.) There’s broad consensus down the columns. We could try to push the grouping a bit more by cutting the dendrogram at some more or less arbitrary point. In the figure above, I cheated slightly by not showing the missing values in the squares. (I needed to average them out in any case to calculate the distance matrix for the clustering.) We could try to put them back in. Doing this in a satisfactory way visually while also having a diverging scale with a midpoint at the average is a little tricky. We need a neutral value for the midpoint but also a null value for missing values. Here’s one way to do it:
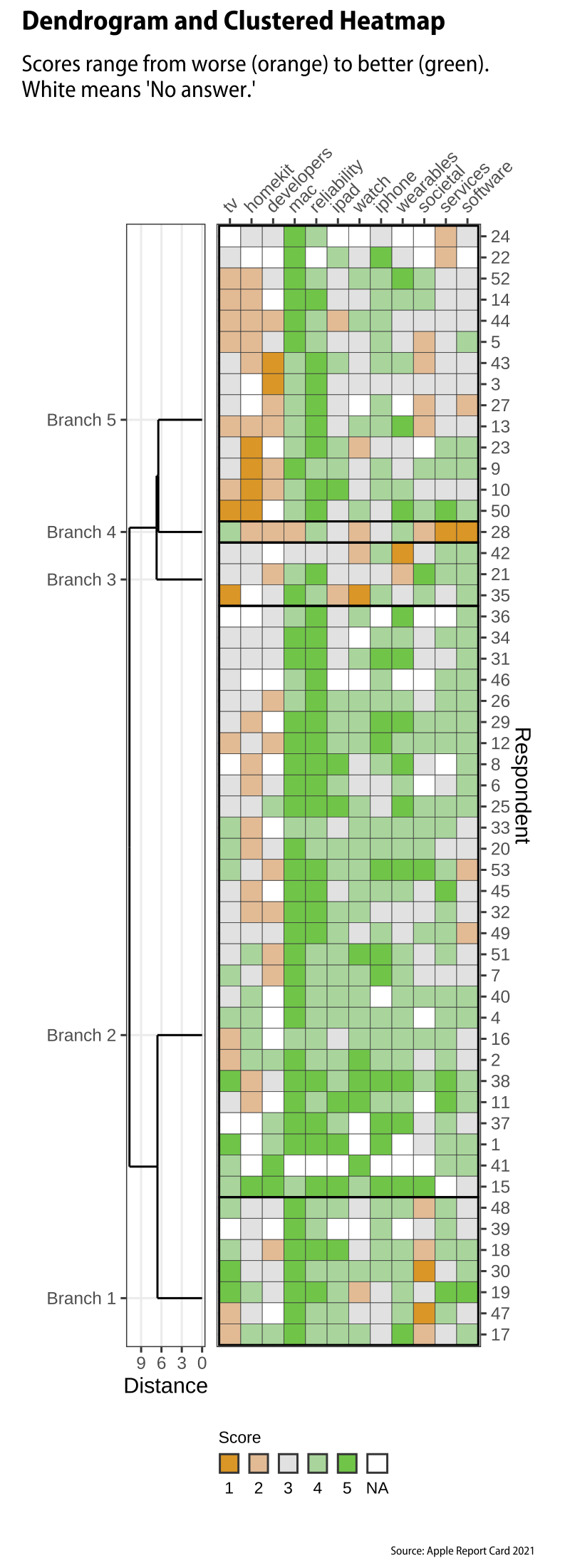
A second version of the clustered dendrogram.
Here the scale runs from orange (bad, 1) to green (best, 5) through gray (average, 3). Missing values are shown in white. I might have used black but I wanted to keep that to outline the groups implied by cutting the dendrogram at a height of about 6. This gives us five notional groups, including #28 in a group all by themselves. The grouping isn’t especially strong. But as I say it’s tempting to see the group at the top as being where the active software developers are clustered along with people who are trying to get the most out of Apple TV and Homekit automation (and hating it). This group is also, on the whole, less positive than average about Apple’s other devices and services. Meanwhile at the bottom are generally contented end-users who are still happy to have gotten a new remote control, and are annoyed at Apple mostly for its performance on broader societal topics, such as the environment and labor relations.
Thanks again to Jason Snell for sharing the anonymized dataset with me. And if you like good reporting, opinion, and analysis of Apple and consumer tech generally, subscribe to Six Colors.