New Orleans and Normalization
My post about Apple’s mobility data from a few days ago has been doing the rounds. (People have been very kind.) Unsurprisingly, one of the most thoughtful responses came from Dr. Drang, who wrote up a great discussion about the importance of choosing the right baseline if you’re going to be indexing change with respect to some time. His discussion of Small Multiples and Normalization is really worth your while.
Dr. Drang’s eye was caught by the case of Seattle, where the transit series was odd in a way that was related to Apple’s arbitrary choice of January 13th as the baseline for its series:
One effect of this normalization choice is to make the recent walking and driving requests in Seattle look higher than they should. Apple’s scores suggest that they are currently averaging 50–65% of what they were pre-COVID, but those are artificially high numbers because the norm was set artificially low.
A better way to normalize the data would be to take a week’s average, or a few weeks’ average, before social distancing and scale all the data with that set to 100.
I’ve been continuing to update my covdata package for R as Apple, Google, and other sources release more data. This week, Apple substantially expanded the number of cities and regions it is providing data for. The number of cities in the dataset went up from about 90 to about 150, for example. As I was looking at that data this afternoon, I saw that one of the new cities was New Orleans. Like Seattle, it’s an important city in the story of COVID-19 transmission within its region. And, as it turns out, even more so than Seattle, its series in this particular dataset is warped by the choice of start date. Here are three views of the New Orleans data: the raw series for each mode, the trend component of an STL time series decomposition, and the remainder component of the decomposition. (The methods and code are the same as previously shown.)
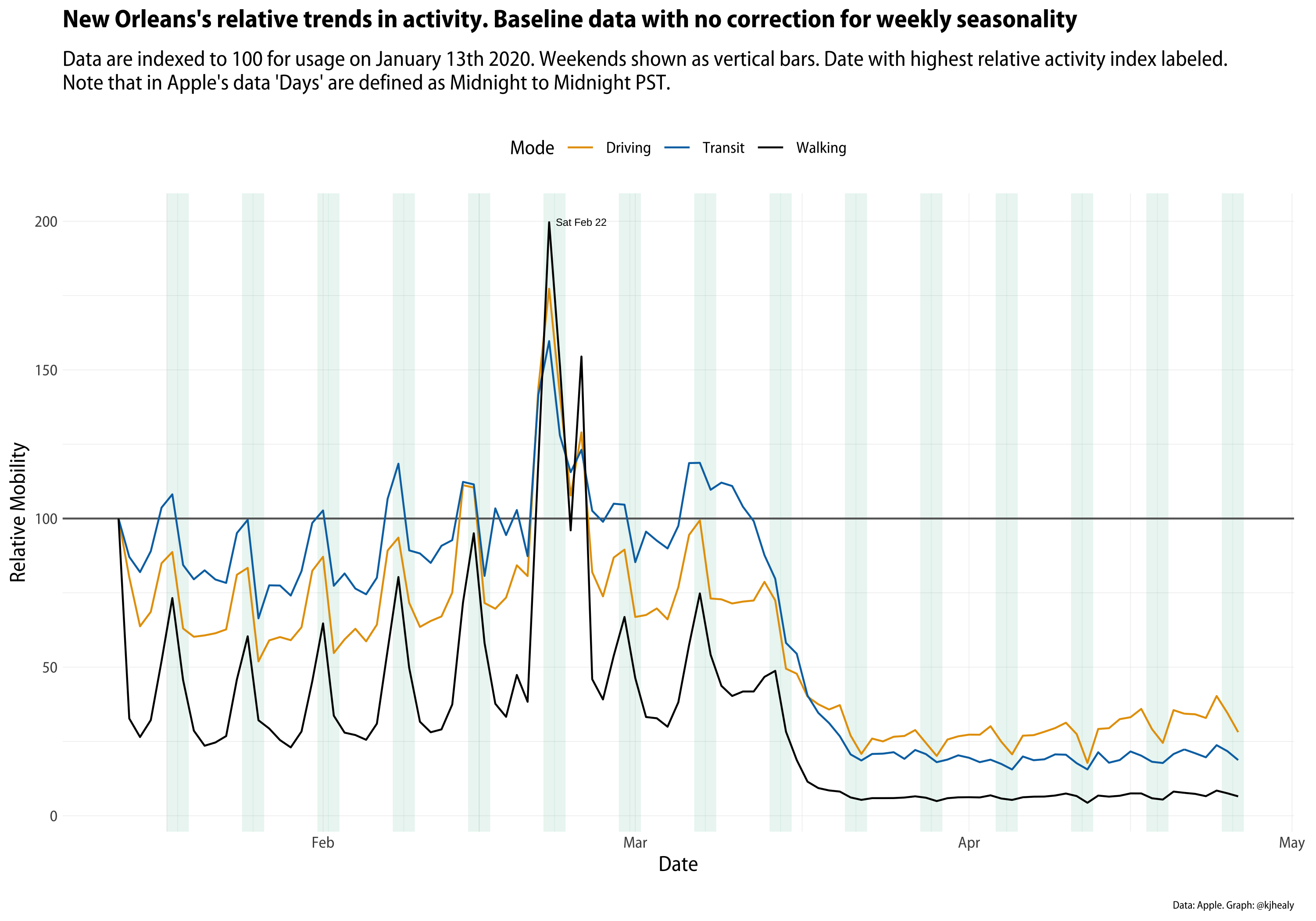
The New Orleans series as provided by Apple. Click or touch to zoom in.
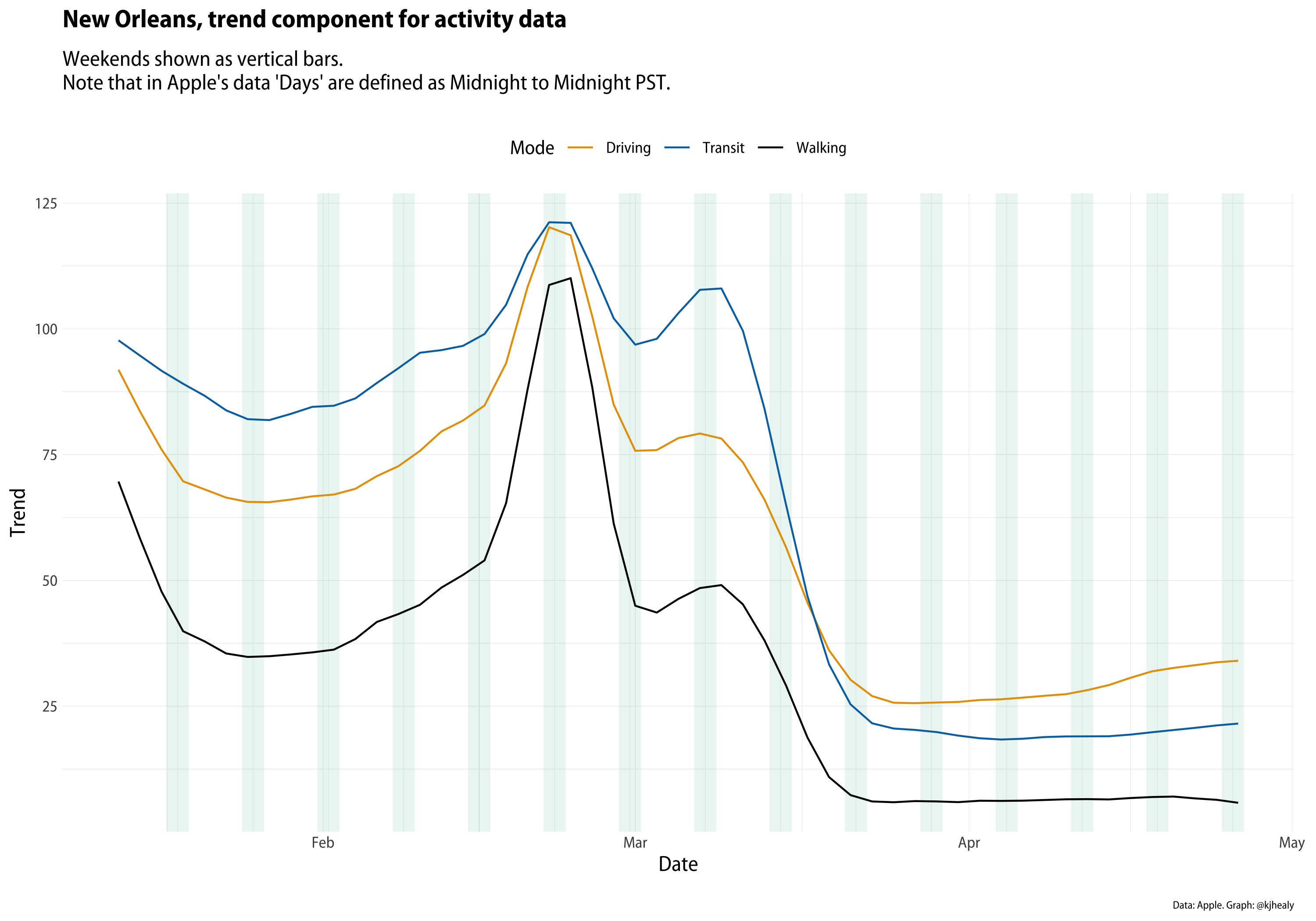
The trend component of the New Orleans series. Click or touch to zoom in.
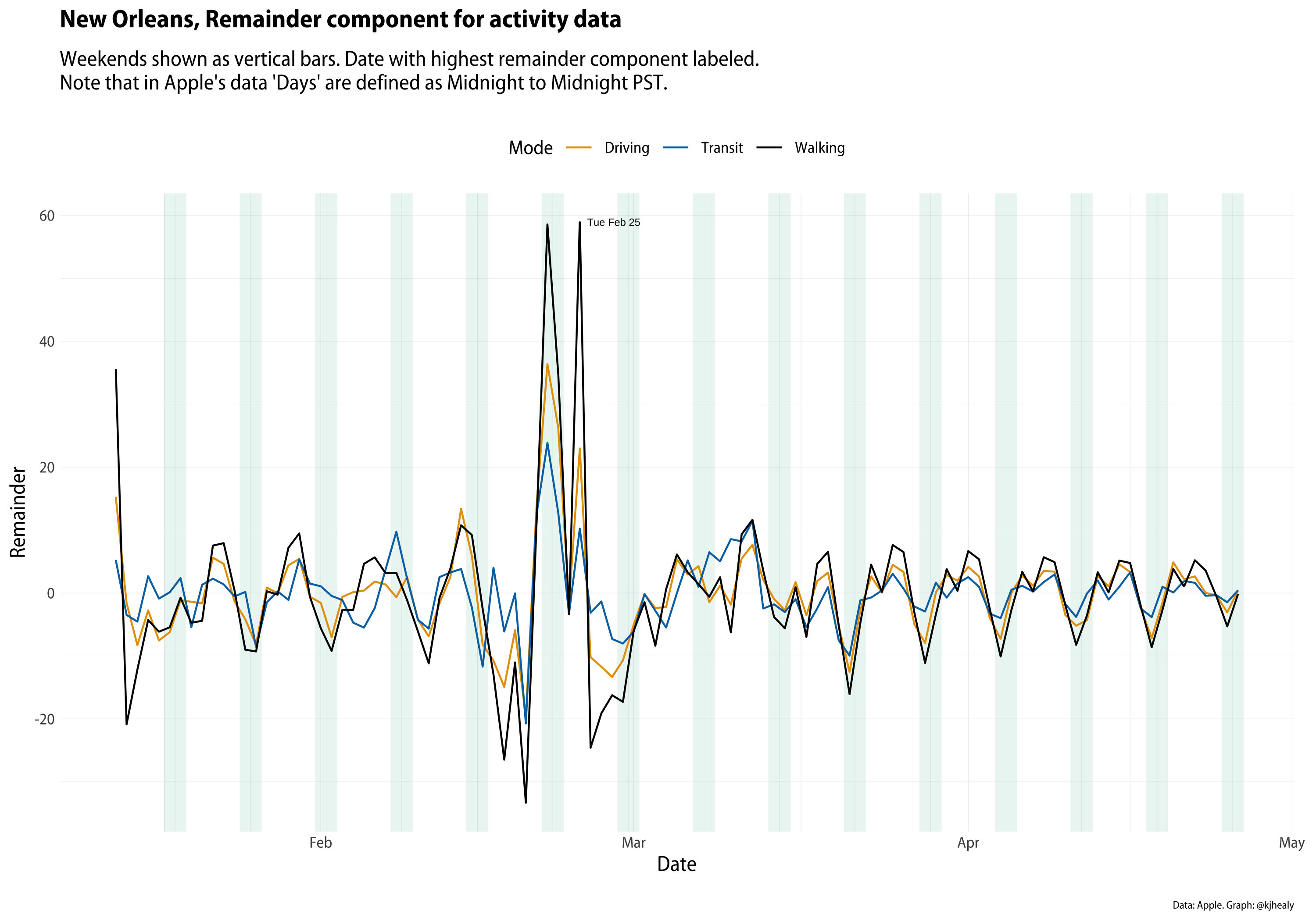
The remainder component of the New Orleans series. Click or touch to zoom in.
Two things are evident right away. First, New Orleans has a huge spike in foot-traffic (and other movement around town) the weekend before Mardi Gras, and on Shrove Tuesday itself. The spike is likely accentuated by the tourist traffic. As I noted before, because Apple’s data is derived from the use of Maps for directions, the movements of people who know their way around town aren’t going to show up.
The second thing that jumps out about the series is that for most of January and February, the city is way, way below its notional baseline. How can weekday foot traffic, in particular, routinely be 75 percentage points below the January starting point?
The answer is that on January 13th, Clemson played LSU in the NCAA National Football Championship at the New Orleans Superdome. (LSU won 42-25.) This presumably brought a big influx of visitors to town, many of whom were using their iPhones to direct themselves around the city. Because Apple chose January 13th as its baseline day, this unusually busy Monday was marked as the “100” mark against which subsequent activity was indexed. Again, as with the strange case of European urban transit, a naive analysis, or even a “sophisticated” one where the researcher did not bother to look at the data first, might easily lead up the garden path.
Dr. Drang has already said most of what I’d say at this point about the value of checking the sanity of one’s starting point (and unlike me, he says it in Python) so I won’t belabor the point. You can see, though, just how huge Mardi Gras is in New Orleans. Were the data properly normalized, the Fat Tuesday spike would be far, far higher than most of the rest of the dataset.