Excess Deaths by Cause
As I was saying the other day, calculating excess deaths can be a tricky business, especially if your focus is on understanding counterfactuals like how many people died of some cause who would not have died due to some other competing risk over the period of interest. Moreover, even setting the counterfactuals aside, the whole business of accurately counting and classifying deaths on the scale of a country as large and variegated as the United States is an enormous challenge in itself. The CDC has been putting out its own estimates of deaths due to COVID-19, and they make various efforts (such as weighting the estimates and so on) to account for delayed reporting and other issues.
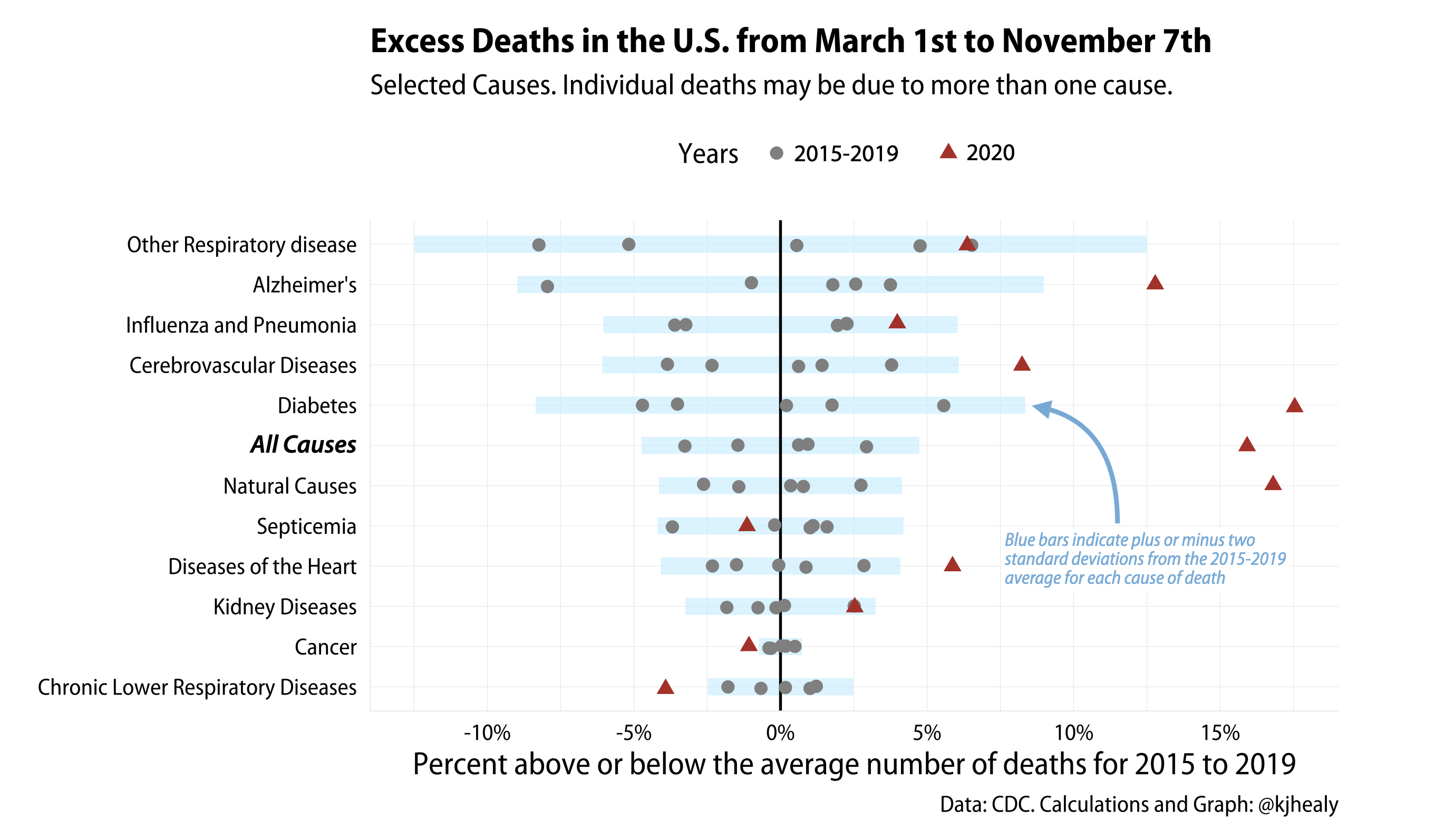
I’ll do something a little simpler here, but I think still useful. Using the weekly counts for 2019-2020 and the final counts for 2015-2019 we can examine selected causes for evidence of excess mortality beyond the baseline of expectations set by the past five years.
Here’s the overall figure.
Excess deaths by Cause.
The idea here is to look at selected non-COVID causes of death (and also All-Cause mortality, i.e. everything) between March 1st and September 1st of this year, in comparison to the same causes between 2015 and 2019. We set the baseline as the mean number of deaths for each cause between 2015 and 2019. Then we calculate how far off each year is from that mean, for each cause. Obviously, it’s not going to be the case that exactly the same number of people die of a given cause each year. But the U.S. is a large country, so there’s a lot of stability from year to year, too. Most causes bounce around their average, but some are more variable than others. Cancer deaths, for instance, do not move around much from year to year. Others, such as Alzheimer’s, and infectious diseases like the ‘flu, are more variable. In the figure here, each gray dot is one of the years from 2015 to 2019, bouncing around that “No different from average” zero line. I’ve banded them with a blue bar showing twice the standard deviation from the mean. While not a super-formal test, anything outside two standard deviations from average is probably worth paying attention to here. We restrict ourselves to deaths that take place from March 1st to September 1st each year, as COVID wasn’t causing fatalities in the US before March. The September 1st cutoff is mostly because data after this point (right now) gets quite noisy, with some states, such as Connecticut and North Carolina, not providing timely provisional counts by cause to the CDC.
I think the patterns here are interesting, and pretty clear. Most of the variation is just bouncing around within five percentage points of the mean, and all of the 2015-2019 years are within two standard deviations of their means. But 2020 is clearly different for many causes. All Cause mortality is everything, and is way up, as are deaths attributed to Diabetes, Alzheimer’s, and Natural Causes. COVID isn’t on the graph as a cause because there’s no 2015-2019 baseline to compare it to, as it didn’t exist. But it is a cause in the 2020 data.
Here’s a closer look at the code and the tables the graph was produced from. As usual, I used R and the covdata package.
|
|
The portion of our excess deaths table for the United States (covering March 1st to September 1st) now looks like this:
|
|
We also make a little tibble of the medians and standard deviations to make drawing the bars more convenient.
|
|
The core of the plot is produced like this:
|
|
COVID and All-Cause mortality
We can also take a look at the df_excess table to see what’s happening with All-Cause mortality and COVID-19 specifically. We need to wrangle the table a little to get the estimates side by side.
|
|
Which (finally) gives us this:
|
|
So in these data (remember, the numbers are updated regularly, we’re looking at March 1 to September 1 only, and this is a rough-and-ready calculation), we have 1,641,133 All-Cause deaths in comparison to a baseline 2015-2019 average of 1,359,816. In this period the raw excess is 281,317 deaths. COVID-19 was listed as a cause of 179,303 of these, leaving a deficit—a remaining excess—of 102,014. Overall excess mortality from March 1st to September 1st is 17.1% above the baseline, with COVID-19 accounting for 10.9 of those percentage points, with a 6.22 percentage point excess distributed across other causes.
Some proportion of the COVID-19 deaths would have succumbed to other causes of death this year. Some proportion of the non-COVID excess deaths are directly or indirectly attributable to COVID. Directly, for example, by someone dying of COVID in a care home, but having the cause recorded as Alzheimer’s or Natural Causes. Indirectly, for instance, by someone suffering a stroke or a heart attack but being reluctant or unable to seek treatment until it was too late. And COVID has also, weirdly, probably resulted in some lives saved as a result of, say, fewer car accidents as a consequence of lockdown. Parceling out these effects, or trying to, will be a job for demographers and public health people for some time to come. But the sheer size of the direct and indirect mortality shock due to COVID just seems undeniable, and my feeling is that it won’t be made to disappear even if its indirect and counterfactual effects get chiseled out or shifted a little at the margins as better data comes in and better estimates become possible.