Sea-surface temperatures in the North Atlantic have been in the news recently as they continue to break records. While there are already a number of excellent summaries and graphs of the data, I thought I’d have a go at making some myself. The starting point is the detailed data made available by the National Centers for Environmental Information, part of NOAA. As always, the sheer volume of high-quality data agencies like this make available to the public is astonishing.
The data is available as daily global observations doing back to September 1st, 1981. Each day’s data is available as a single file in subdirectories organized by year-month. It’s all here. Each file is about 1.6MB in size. There are more than fifteen thousand of them.
To do it by hand, we can make a folder called raw in our project and then get all the data, preserving its subdirectory structure, with a wget command like this:
This tries to be polite with the NOAA. (I think its webserver is also lightly throttled in any case, but it never hurts to be nice.) The switches --no-parent -r -l inf tell wget not to move upwards in the folder hierarchy, but to recurse downwards indefinitely. The --wait 5 --random-wait jointly enforce a five-second wait time between requests, randomly varying between 0.5 and 1.5 times the wait period. Downloading the files this way will take several days of real time downloading, though of course much less in actual file transfer time.
The netCDF data format
The data are netCDF files, an interesting and in fact quite nice self-documenting binary file format. These files have regular arrays of data of some n-dimensional size, e.g. latitude by longitude, with measures that can be thought of as being stacked on the array. (E.g. a grid of points with a measure at each point for surface temperature, sea ice extent, etc, etc). So you have the potential to have big slabs of data that you can then summarize by aggregating on some dimension or other.
The ncdf4 package can read them in R, though as it turns out we won’t use this package for the analysis. Here’s what one file looks like:
This is the file for May 27th, 1984. As you can see, there’s a lot of metadata. Each variable is admirably well-documented. The key information for our purposes is that we have a grid of 1440 by 720 lat-lon points. There are two additional dimensions—time and elevation (zlev)—but these are both just 1 for each particular file, because every file is observations at elevation zero on a particular day. There are four measures at each point: sea surface temperature anomalies, the standard deviation of the sea surface temperature estimate, sea ice concentration (as a percentage), and sea surface temperature (in degrees Celsius). So we have four bits of data for each grid point on our 1440 * 720 grid, which makes for just over 4.1 million data points per day since 1981.
Processing the Data
We read in the filenames and see how many we have:
What we want to do is read in all this data and aggregate it so that we can take, for instance, the global average for each day and plot that trend for each year. Or perhaps we want to do that for specific regions of the globe, either defined directly by us in terms of some latitude and longitude polygon, or taken from the coordinates of some conventional division of the world’s oceans and seas into named areas.
Our tool of choice is the Terra package, which is designed specifically for this kind of data. It has a number of methods for conveniently aggregating and cutting into arrays of geospatial data. The netCDF4 package has a lot of useful features, too, but for the specific things we want to do Terra’s toolkit is quicker. One thing it can do, for example, is naturally aggregate over-time layers into single “bricks” of data, and then quickly slice, summarize, or calculate on these arrays.
So, let’s chunk our filenames into units of 25 days or so. This will make the multi-file operation we’re about to perform run faster, because we can read in and operate on a raster of 25 days at once instead of doing the same thing on 25 separate rasters. There’s probably an optimal chunk size, but I didn’t search too hard for it.
1
2
3
## This one gives you an unknown number of chunks each with approx n elementschunk<-function(x,n)split(x,ceiling(seq_along(x)/n))chunked_fnames<-chunk(all_fnames,25)
Next, we write a function to process a raster file that terra creates. It calculates the area-weighted means of the layer variables. We have to weight our mean temperature calculation by area (instead of just directly taking the average of all the points) because the area of the degree-denominated grids gets smaller the closer you get to the poles. (This is because, some current views notwithstanding, the Earth is round.)
layerinfo<-tibble(num=c(1:4),raw_name=c("anom_zlev=0","err_zlev=0","ice_zlev=0","sst_zlev=0"),name=c("anom","err","ice","sst"))process_raster<-function(fnames,crop_area=c(-80,0,0,60),layerinfo=layerinfo){tdf<-terra::rast(fnames)|>terra::rotate()|># Convert 0 to 360 lon to -180 to +180 lonterra::crop(crop_area)# Manually crop to a defined box. Default is roughly N. Atlantic lat/lon boxwts<-terra::cellSize(tdf,unit="km")# For scaling. Because the Earth is round.# global() calculates a quantity for the whole grid on a particular SpatRaster# so we get one weighted mean per file that comes inout<-data.frame(date=terra::time(tdf),means=terra::global(tdf,"mean",weights=wts,na.rm=TRUE))out$var<-rownames(out)out$var<-gsub("_.*","",out$var)out<-reshape(out,idvar="date",timevar="var",direction="wide")colnames(out)<-gsub("weighted_mean\\.","",colnames(out))out}
For a single file, this gives us one number for each variable:
1
2
3
4
5
6
# World box (60S to 60N)world_crop_bb<-c(-180,180,-60,60)process_raster(all_fnames[10000],crop_area=world_crop_bb)#> date anom err ice sst#> anom_zlev=0 2009-01-20 0.01397327 0.1873972 0.6823713 20.26344
We need to do this for all the files so we get complete dataset. We take advantage of the futureverse to parallelize the operation, because doing this with 15,000 files is going to take a bit of time. Then at the end we clean it up a little bit.
Now we have a time series for each of the variables daily from 1981 to yesterday.
Calculating values for all the world’s seas and oceans
We can do a little better though. What if we wanted to get these average values for the seas and oceans of the world? For that we’d need a map defining the conventional boundaries of those areas of water, which we’d then need to covert to raster format. After that, we’d slice up our global raster by the ocean and sea boundaries, and calculate averages for those areas.
Then we rasterize the polygons with a function from terra:
1
2
3
4
5
6
7
## Rasterize the seas polygons using one of the nc files## as a reference grid for the rasterization processone_raster<-all_fnames[1]seas_vect<-terra::vect(seas)tmp_tdf_seas<-terra::rast(one_raster)["sst"]|>rotate()seas_zonal<-rasterize(seas_vect,tmp_tdf_seas,"NAME")
Now we can use this data as the grid to do zonal calculations on our data raster. To use it in a parallelized calculation we need to wrap it, so that it can be found by the processes that future_map() will spawn. We write a new function to do the zonal calculation. It’s basically the same as the global one above.
seas_zonal_wrapped<-wrap(seas_zonal)process_raster_zonal<-function(fnames){d<-terra::rast(fnames)wts<-terra::cellSize(d,unit="km")# For scalinglayer_varnames<-terra::varnames(d)# vector of layersdate_seq<-rep(terra::time(d))# vector of dates# New colnames for use post zonal calculation belownew_colnames<-c("sea",paste(layer_varnames,date_seq,sep="_"))# Better colnamestdf_seas<-d|>terra::rotate()|># Convert 0 to 360 lon to -180 to +180 lonterra::zonal(unwrap(seas_zonal_wrapped),mean,na.rm=TRUE)colnames(tdf_seas)<-new_colnames# Reshape to longtdf_seas|>tidyr::pivot_longer(-sea,names_to=c("measure","date"),values_to="value",names_pattern="(.*)_(.*)")|>tidyr::pivot_wider(names_from=measure,values_from=value)}
And we feed our chunked vector of filenames to it:
Now we have properly-weighted daily averages for every sea and ocean since September 1981. Time to make some pictures.
Global Sea Surface Mean Temperature Graph
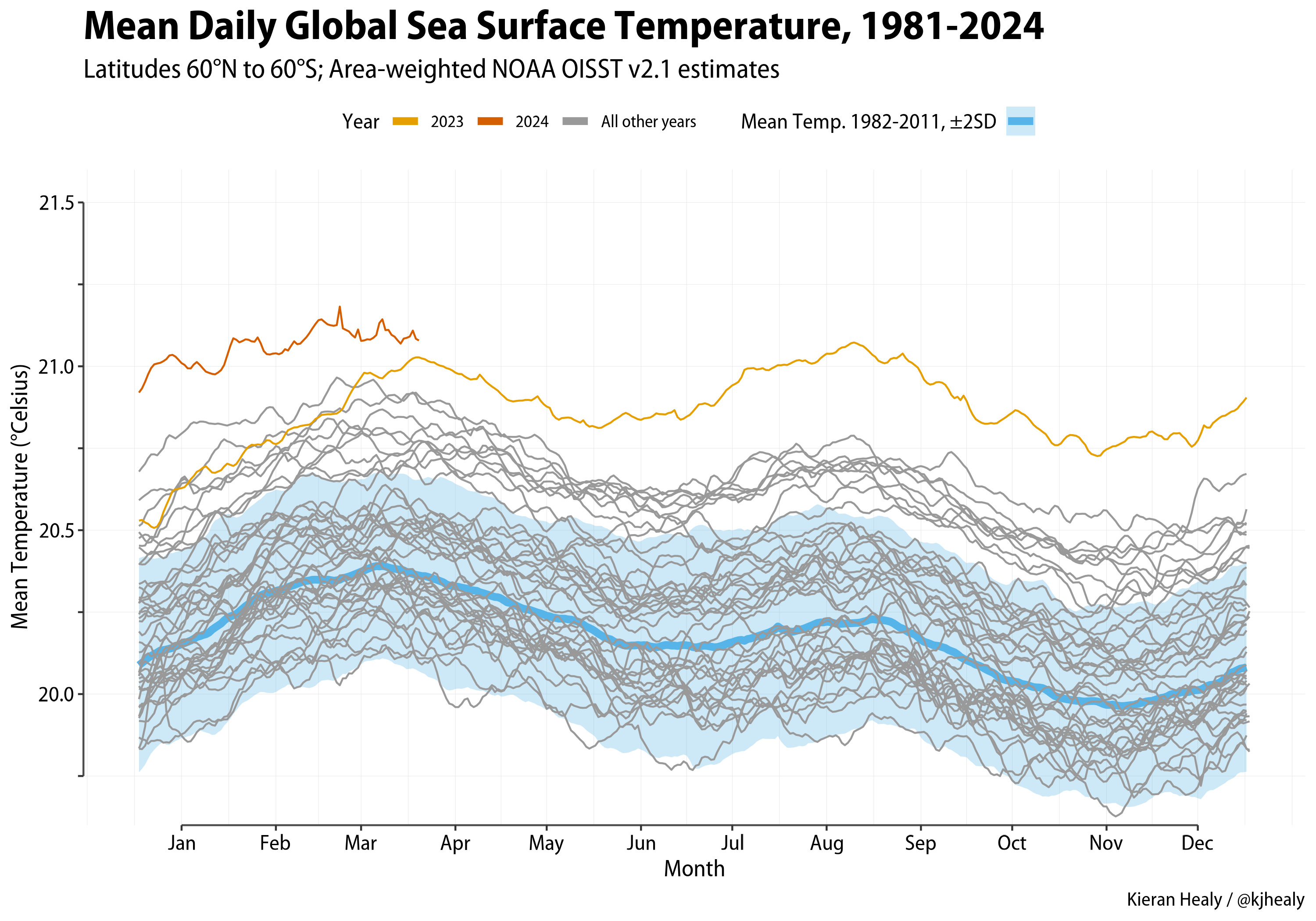
To make a graph of the global daily mean sea surface temperature we can use the world_df object we made. The idea is to put the temperature on the y-axis, the day of the year on the x-axis, and then draw a separate line for each year. We highlight 2023 and (the data to date for) 2024. And we also draw a ribbon underlay showing plus or minus two standard deviations of the global mean.
colors<-ggokabeito::palette_okabe_ito()## Labels for the x-axismonth_labs<-seameans_df|>filter(sea=="North Atlantic Ocean",year==2023,day==15)|>select(date,year,yrday,month,day)|>mutate(month_lab=month(date,label=TRUE,abbr=TRUE))## Average and sd ribbon dataworld_avg<-world_df|>filter(year>1981&year<2012)|>group_by(yrday)|>filter(yrday!=366)|>summarize(mean_8211=mean(sst,na.rm=TRUE),sd_8211=sd(sst,na.rm=TRUE))|>mutate(fill=colors[2],color=colors[2])## Flag years of interestout_world<-world_df|>mutate(year_flag=case_when(year==2023~"2023",year==2024~"2024",.default="All other years"))out_world_plot<-ggplot()+geom_ribbon(data=world_avg,mapping=aes(x=yrday,ymin=mean_8211-2*sd_8211,ymax=mean_8211+2*sd_8211,fill=fill),alpha=0.3,inherit.aes=FALSE)+geom_line(data=world_avg,mapping=aes(x=yrday,y=mean_8211,color=color),linewidth=2,inherit.aes=FALSE)+scale_color_identity(name="Mean Temp. 1982-2011, ±2SD",guide="legend",breaks=unique(world_avg$color),labels="")+scale_fill_identity(name="Mean Temp. 1982-2011, ±2SD",guide="legend",breaks=unique(world_avg$fill),labels="")+ggnewscale::new_scale_color()+geom_line(data=out_world,mapping=aes(x=yrday,y=sst,group=year,color=year_flag),inherit.aes=FALSE)+scale_color_manual(values=colors[c(1,6,8)])+scale_x_continuous(breaks=month_labs$yrday,labels=month_labs$month_lab)+scale_y_continuous(breaks=seq(19.5,21.5,0.5),limits=c(19.5,21.5),expand=expansion(mult=c(-0.05,0.05)))+geom_line(linewidth=rel(0.7))+guides(x=guide_axis(cap="both"),y=guide_axis(minor.ticks=TRUE,cap="both"),color=guide_legend(override.aes=list(linewidth=2)))+labs(x="Month",y="Mean Temperature (°Celsius)",color="Year",title="Mean Daily Global Sea Surface Temperature, 1981-2024",subtitle="Latitudes 60°N to 60°S; Area-weighted NOAA OISST v2.1 estimates",caption="Kieran Healy / @kjhealy")+theme(axis.line=element_line(color="gray30",linewidth=rel(1)),plot.title=element_text(size=rel(1.9)))ggsave(here("figures","global_mean.png"),out_world_plot,height=7,width=10,dpi=300)
Global mean sea surface temperature 1981-2024
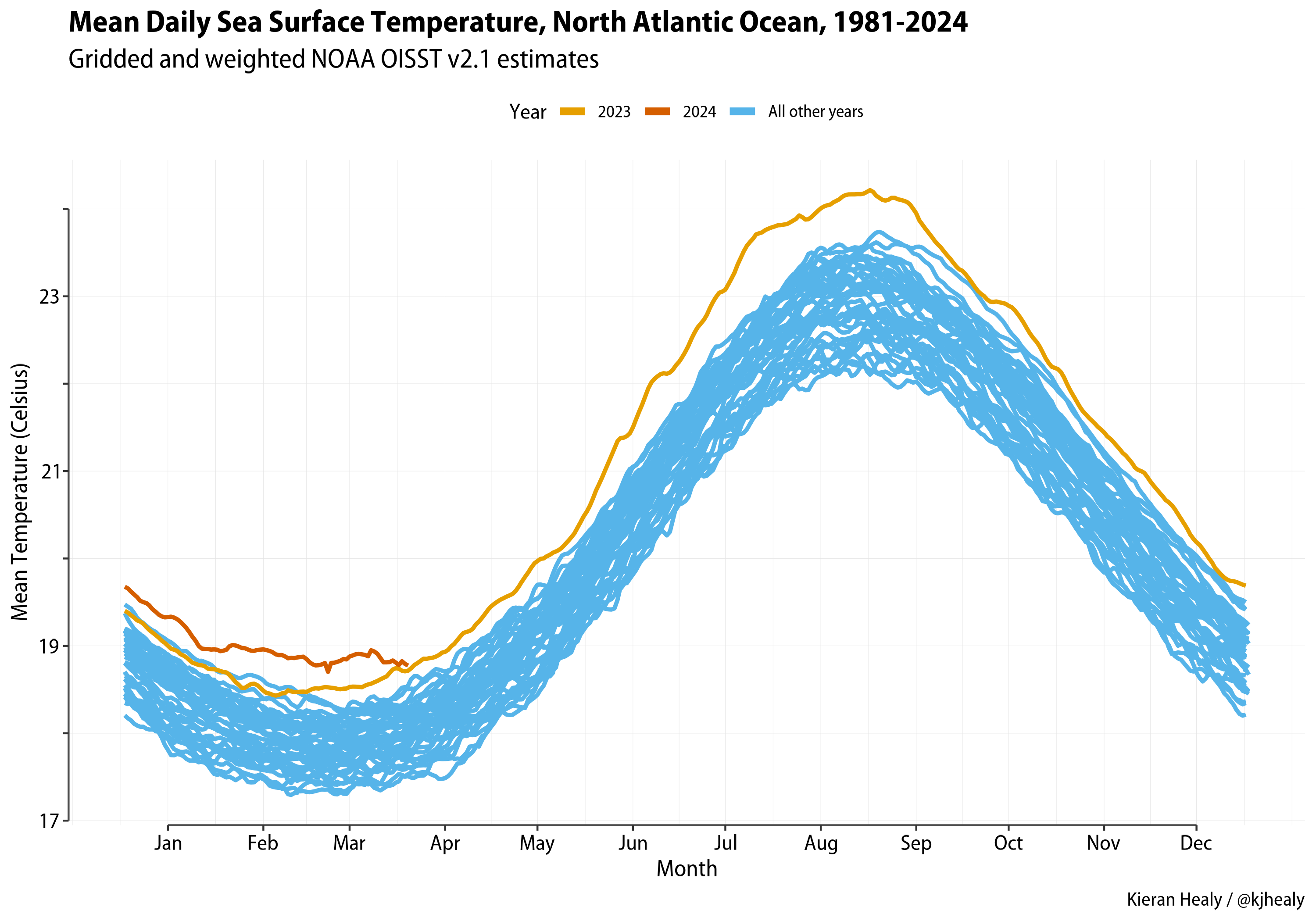
The North Atlantic
We can slice out the North Atlantic by name from seameans_df and make its graph in much the same way. For variety we can color most of the years blue, to lean into the “Great Wave off Kanagawa” (or Rockall?) vibe.
## All the world's oceans and seasout<-seameans_df|>mutate(year_flag=case_when(year==2023~"2023",year==2024~"2024",.default="All other years"))|>ggplot(aes(x=yrday,y=sst,group=year,color=year_flag))+geom_line(linewidth=rel(0.5))+scale_x_continuous(breaks=month_labs$yrday,labels=month_labs$month_lab)+scale_color_manual(values=colors[c(1,6,2)])+guides(x=guide_axis(cap="both"),y=guide_axis(minor.ticks=TRUE,cap="both"),color=guide_legend(override.aes=list(linewidth=1.4)))+facet_wrap(~reorder(sea,sst),axes="all_x",axis.labels="all_y")+labs(x="Month of the Year",y="Mean Temperature (Celsius)",color="Year",title="Mean Daily Sea Surface Temperatures, 1981-2024",subtitle="Area-weighted 0.25° grid estimates; NOAA OISST v2.1; IHO Sea Boundaries",caption="Data processed with R; Figure made with ggplot by Kieran Healy / @kjhealy")+theme(axis.line=element_line(color="gray30",linewidth=rel(1)),strip.text=element_text(face="bold",size=rel(1.4)),plot.title=element_text(size=rel(1.525)),plot.subtitle=element_text(size=rel(1.1)))ggsave(here("figures","all_seas.png"),out,width=40,height=40,dpi=300)
All the world’s oceans and seas, because why not.
The full code for the data processing and the graphs is available on GitHub.