Upset Plots
The other day Nature reported some preliminary results from a study of COVID-19 symptoms that’s being carried out via a phone app. The report noted that loss of sense of smell (or “Anosmia”) seemed to be a common symptom. The report was accompanied by this graphic, showing the co-occurrence of symptoms in about 1,700 self-reports via the app.
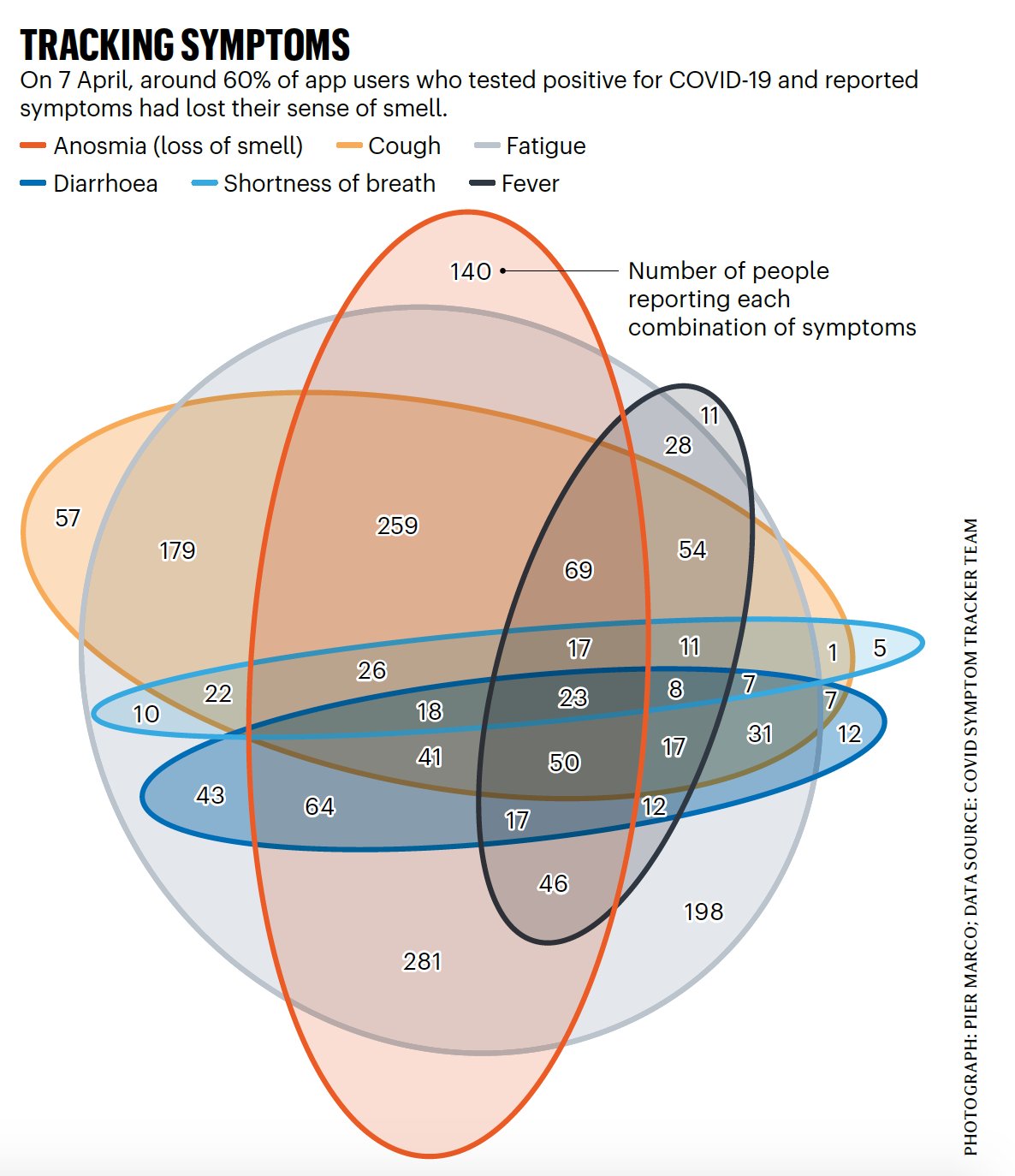
A species of Venn Diagram showing the co-occurrence of reported COVID-19 symptoms.
(Again, please bear in mind that these are preliminary results from the users of a single smartphone app.)
I think it’s fair to say that this way of representing the data is pushing the Venn Diagram approach to its limits. It’s hard to get a sense of what’s going on. That said, representing what are in effect tables of cross-classified counts or frequencies is one of those aspects of data visualization that is surprisingly hard to do effectively. If you have a large number of categories and cross-classifications of discrete measures, things get messy very fast. Continuous data are much easier to display, by comparison.
Still, we can do better. One familiar option would be a heatmap of some sort, showing a matrix of symptoms—perhaps clustered how often they occur together—with the cells shaded by the counts or frequencies. More recently, the upset plot, developed by Lex et al (2014), has emerged as a useful alternative. An upset plot arranges your co-occurring variables into sets and shows you a bar chart of their frequency. The trick is that it tries to make it easy to see the elements that make up the set.
There are several implementations of upset plots in R. I’m going to use the Complex UpSet package, but they’re all good. Check out UpSetR, and ggupset as well.
I used a spreadsheet to copy out the data from the Nature report, and then loaded it in to R.
|
|
We have six basic symptoms (“Breath” means “Shortness of Breath”). They occur in various combinations. We need to get this data into a shape we can work with. We have two tasks. First, it will be convenient to convert this summary back into an observation-level table. The tidyr package has a handy function called uncount that will do this for us. However, we can’t do that directly. Think of the table as showing counts of where various combinations of symptoms are TRUE. Implicitly, where we don’t see a symptom, it’s implicitly FALSE in those cases where it isn’t there. For example, in the first row, the 140 patients reporting Anosmia are implicitly also reporting they don’t have any of the other five symptoms. If we don’t get those implicit negatives back, we won’t get a proper picture of the clustering.
So, we’re going to generate table of TRUE and FALSE values for our symptom combinations.
|
|
OK, so with that table in place, we can use the uncount() function to turn our summary back into quasi-individual-level data:
|
|
If we hadn’t done that tabulation, uncount would have given us the wrong answers. Ask me how I know!
Now that we’ve reconstituted the data, we can draw our graph.
|
|
An UpSet plot showing the co-occurrence of reported COVID-19 symptoms. Click or touch to zoom.
The plot has three pieces. The bar chart shows the number of people in the data who reported some particular combination of symptoms. Each bar is a different combination. Underneath it is a graphical table showing what those combinations are. Each row is one of our six symptoms: Fatigue, Anosmia, Cough, Fever, Diarrhea, and (shortness of) Breath. The black dots and lines show the combination of symptoms that make up each cluster or subset of symptoms. Reading from left to right, we can see that the most common subset of symptoms is the combination of Fatigue and Anosmia, and nothing else. A total of 281 respondents reported this combination. Next is Fatigue, Anosmia, and Cough, with 259 reports, followed by Fatigue alone with 198. And so on across the table. You can see, for example, that there are 23 reports of all six symptoms, and only one report of just the combination of Cough and shortness of Breath.
The third component of the plot is the smaller bar chart to the left of the graphical table. This shows the unconditional frequency count of each symptom across all subsets. You can see that almost everyone reported suffering from Fatigue, for instance, and that Shortness of Breath was the least commonly-reported symptom in absolute terms.
I think upset plots are very useful, on the whole. They clearly outperform Venn diagrams when there’s more than a few overlapping sets, and they avoid some of the problems associated with heatmaps, too. Nicholas Tierney puts them to very good use in naniar, his package for visualizing missing data. The technique doesn’t make the problems with visualizing cross-classified counts magically disappear, of course. If you have a large number of intersecting groups it will become unwieldy as well. But then of course you’d start to look for ways to focus on the intersections that matter most, or on alternative ways of ordering the combinations, and so on. (The upset packages have some of these methods built in.) In the meantime, it’s often your best option for this kind of task.
The code and data used in this post are available on GitHub.