gssr Update
Update (April 15th 2024)
gssr is now two packages: gssr and gssrdoc. They’re also available as binary packages via R-Universe which means they will install much faster. See this post for details.
The General Social Survey, or GSS, is one of the cornerstones of US public opinion research and one of the most-analyzed datasets in Sociology. My colleague Steve Vaisey aptly describes it as the Hubble Space Telescope of American social science. It is routinely used in research, in teaching, and as a reference point in discussions about changes in American society since the early 1970s. It is also a model of open, public data. The National Opinion Research Center already provides many excellent tools for working with the data, and has long made it freely available to researchers. Casual users of the GSS can examine the GSS Data Explorer, and social scientists can download complete datasets directly. At present, the GSS is provided to researchers in a variety of commercial formats: Stata (.dta), SAS, and SPSS (.sav). It’s not too difficult to get the data into R using the Haven package, but it can be a little annoying to have to do it repeatedly, or across projects. After doing it one too many times, a few years ago I got tired of it and I made an R package instead, gssr. Full details are available at the gssr homepage.
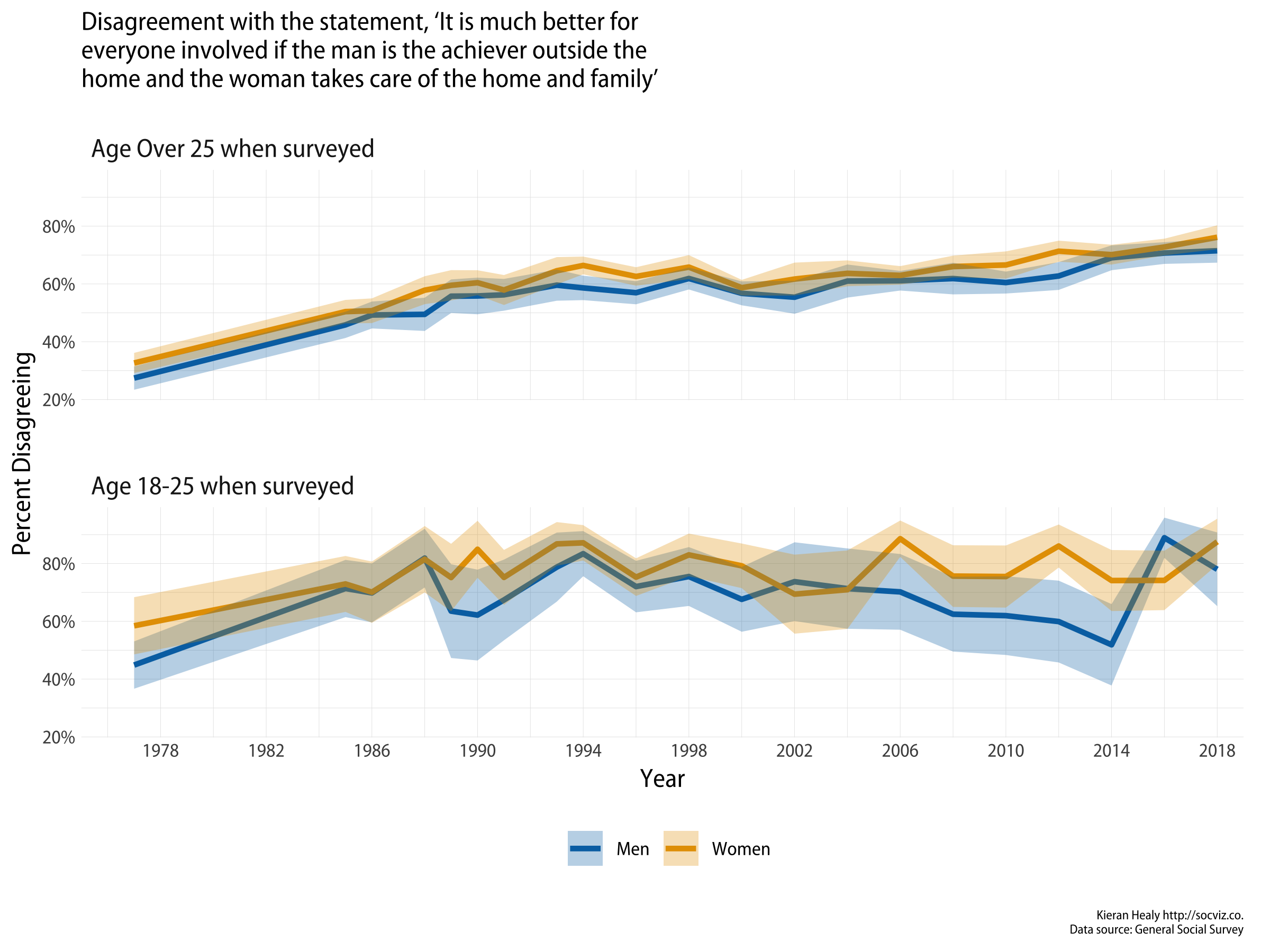
GSS ‘fefam’ variable trends over time
This update to the gssr package (version 0.4) provides the GSS Cumulative Data File (1972-2022), three GSS Three Wave Panel Data Files (for panels beginning in 2006, 2008, and 2010, respectively), and the 2020 panel file. This version of also integrates survey codebook information about variables directly into R’s help system, allowing them to be accessed via the help browser or from the console with ?, as if they were functions or other documented objects.
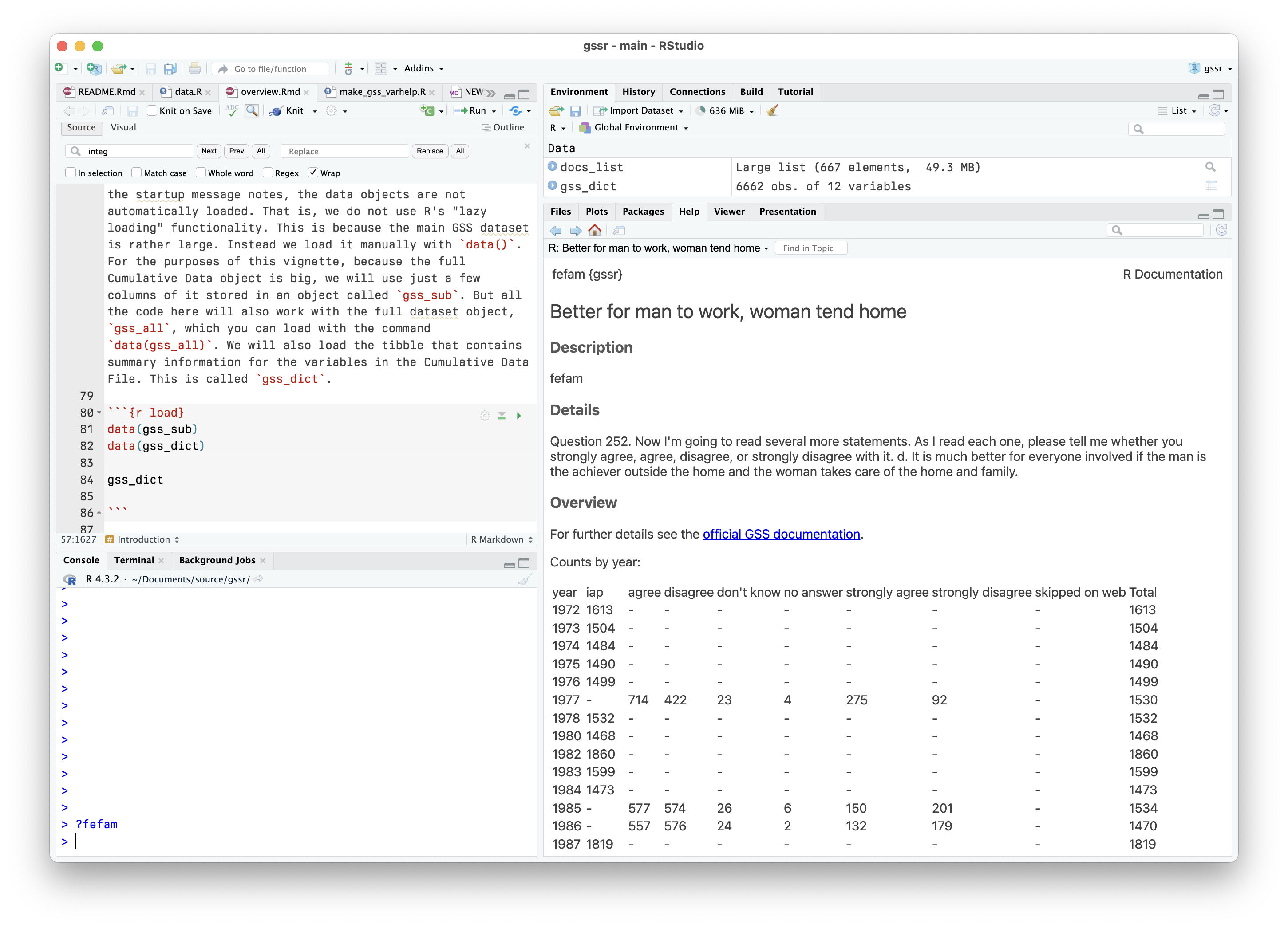
GSS ‘fefam’ variable information inside R’s help system.
The gssr package makes the GSS a little more accessible to users of R, the free software environment for statistical computing. In a small way it helps make the GSS even more open than it already is.