Us Monthly Births
Yesterday I came across Aaron Penne’s collection of very nice data visualizations, one of which was of monthly births in the United States since 1933. He made a tiled heatmap of the data, taking care when calculating the average rate to correct for the varying number of days in different months. Aaron works in Python, so I took the opportunity to play around with the data and redo the plots in R. The code and data are on Github.
First, here’s the monthly heatmap. I use one of the Viridis palettes, as it has very nice contrast properties.
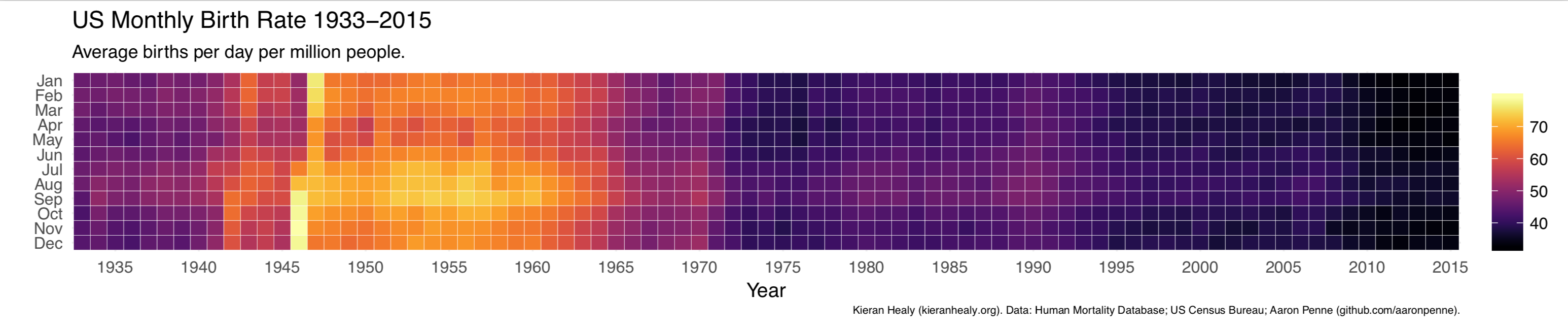
Monthly births in the United Dates, 1933-2015.
While we’re at it, we can also make a version of this plot that’s oriented vertically. This might be nice to view on a portrait-oriented screen like a tablet or phone

Monthly births in the United Dates, 1933-2015, vertically oriented.
Fancy tiled heatmaps are nice, but it can be hard to beat an old-fashioned time-series:
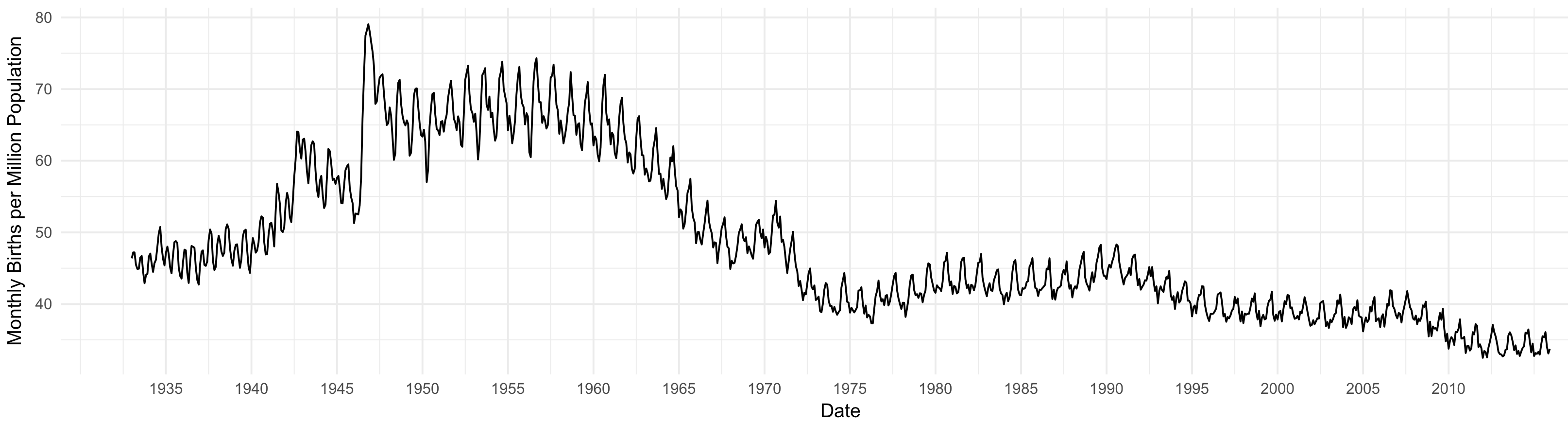
Monthly births in the United Dates, 1933-2015. Time series plot.
In this version you can really see that the Baby Boom has two beginnings—about nine months after December 1941, when the US joined the war, and then in earnest about nine months after December 1945.
With time-series data like this, William Cleveland’s LOESS-based decomposition often gives nice results, so I ran that on the data. (It’s in R as the stl() function). The series gets decomposed into trend, seasonal, and remainder components. Here’s what that looks like.
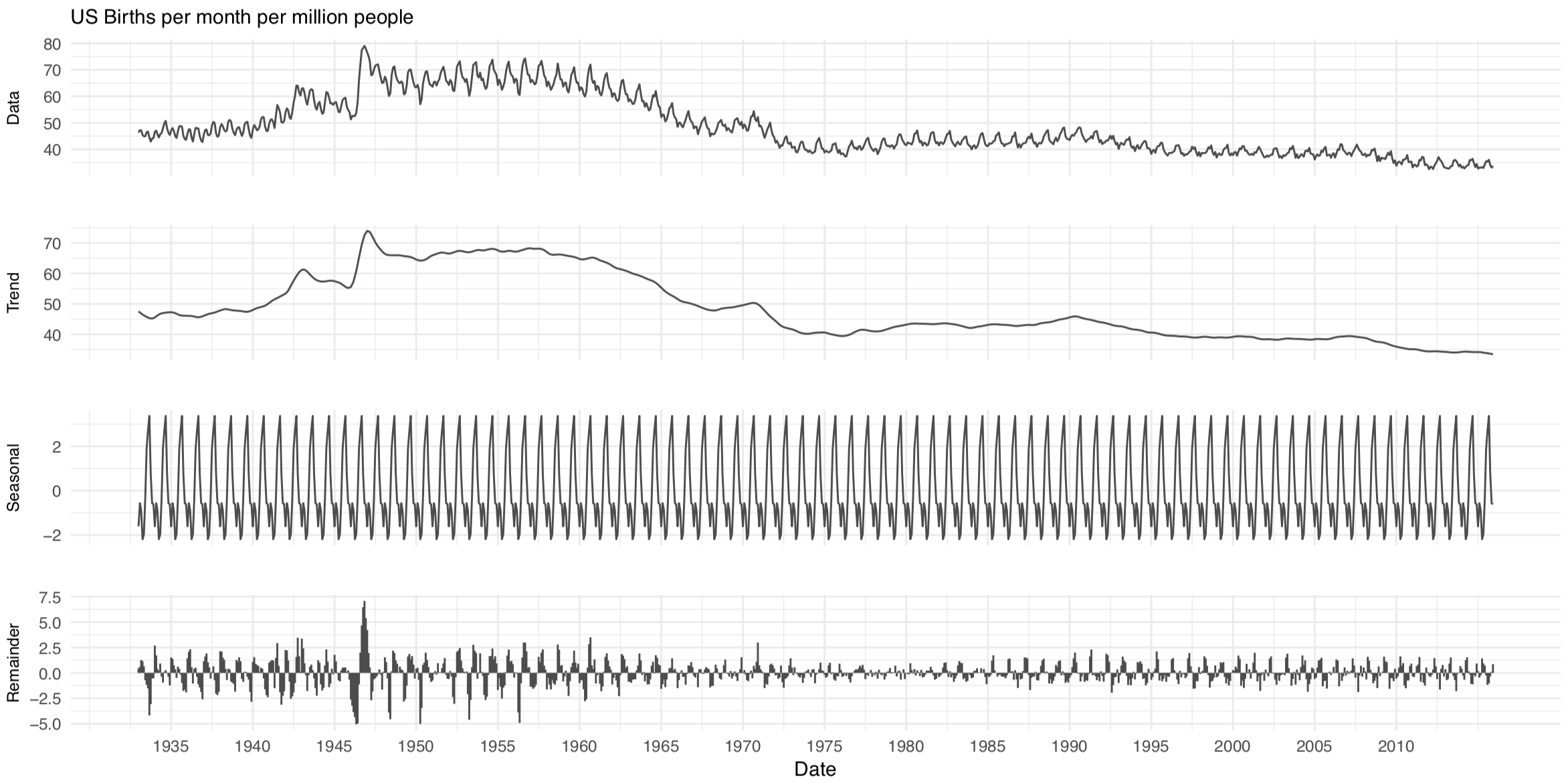
Monthly births in the United Dates, 1933-2015. Time series decomposition.
When interpreting the decomposition, bear in mind that each panel has its own y-axis, appropriate to the range of the element being plotted. This means the Data and Trend panels are more or less comparable, but the Seasonal and Remainder components are on different (and much narrower) scales.