Filling Ordered Facets From the Bottom Row
On Twitter the other day, Philip Cohen put up some data on changes in Bachelor’s degrees awarded between 1995 and 2015. The data come from the National Center for Education Statistics. It seemed like a good candidate for drawing as a figure, so I had a go at it:
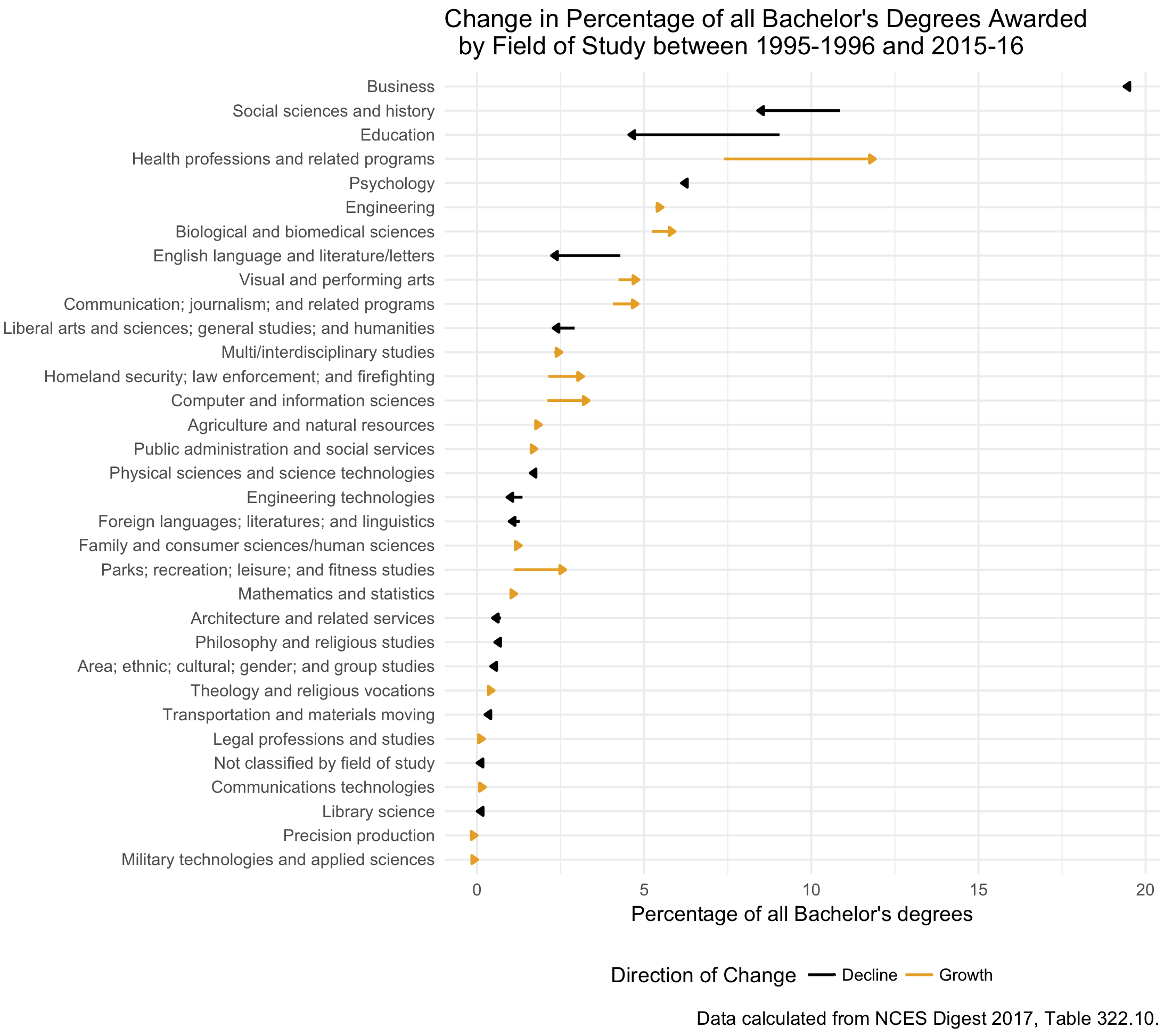
Changes in the number of Bachelor’s degrees awarded over the past twenty years.
Afterwards, I was messing around with the data and wanted to draw some time-series plots for the various subject areas the NCES tracks. After cleaning up the data, we end up with a tidy table that looks like this:
|
|
The data and code for everything here (including the figure above) is available on Github, by the way.
What we want is a small-multiple of the trends for each subject area with more than two percent of degrees conferred. That’s what the cutoff variable is for. When we create small multiples, we almost always want to order them in some sensible way. This is almost never the default of alphabetically by category. Instead, we will reorder the panels (the facets, in ggplot’s terms) by some statistic of interest—most often, the mean value of the variable we’re showing. We set up some labels (because we’ll be reusing them) and draw the plot. The key bit is the ~ reorder(field_of_study, -yr_pct) instruction.
|
|
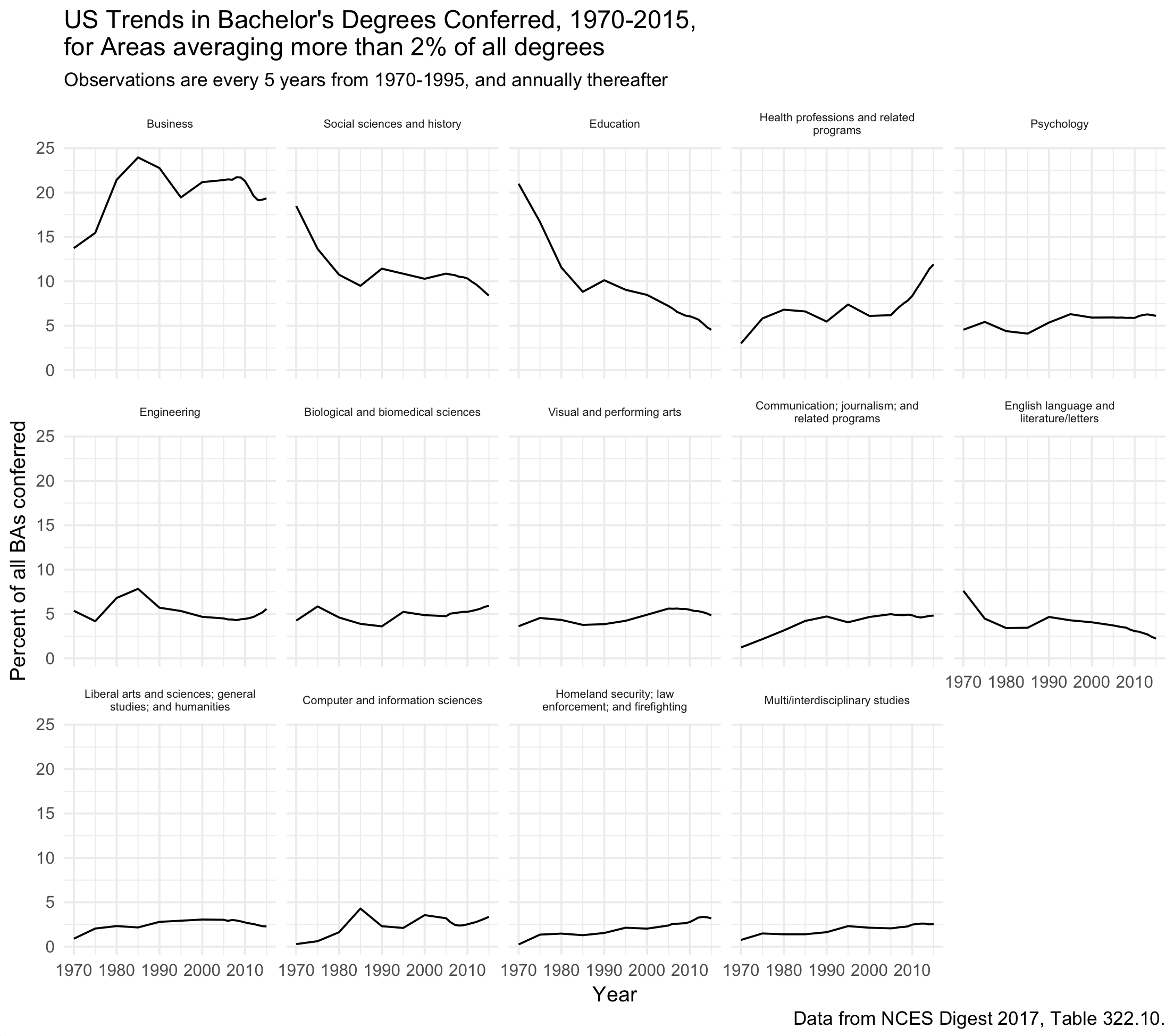
Facets ordered by the mean value of the time series, from top left to bottom right. The bottom row is not completely filled.
The result is a nice graph. R and ggplot have taken care of the layout for us. As is often the case, the number of categories doesn’t fit evenly into the number of rows in the plot. There’s a space left over in the bottom row. By default, ggplot will add x-axis labels to the next available panel on the row above (“English Language and Literature/Letters”).
Again on Twitter, DrDrang asked if there was a way, in effect, to force the bottom row of the plot to be filled in. Ggplot’s small multiples intelligently minimize redundancy in x- and y-axes labeling, but maybe we don’t like having that gap at the bottom and the associated need for another labeled axis in the row above. The facet_wrap() function has an as.table argument that’s set to TRUE by default. The help says
If
TRUE, the default, the facets are laid out like a table with highest values at the bottom-right. IfFALSE, the facets are laid out like a plot with the highest value at the top-right.
We can set as.table to FALSE:
|
|
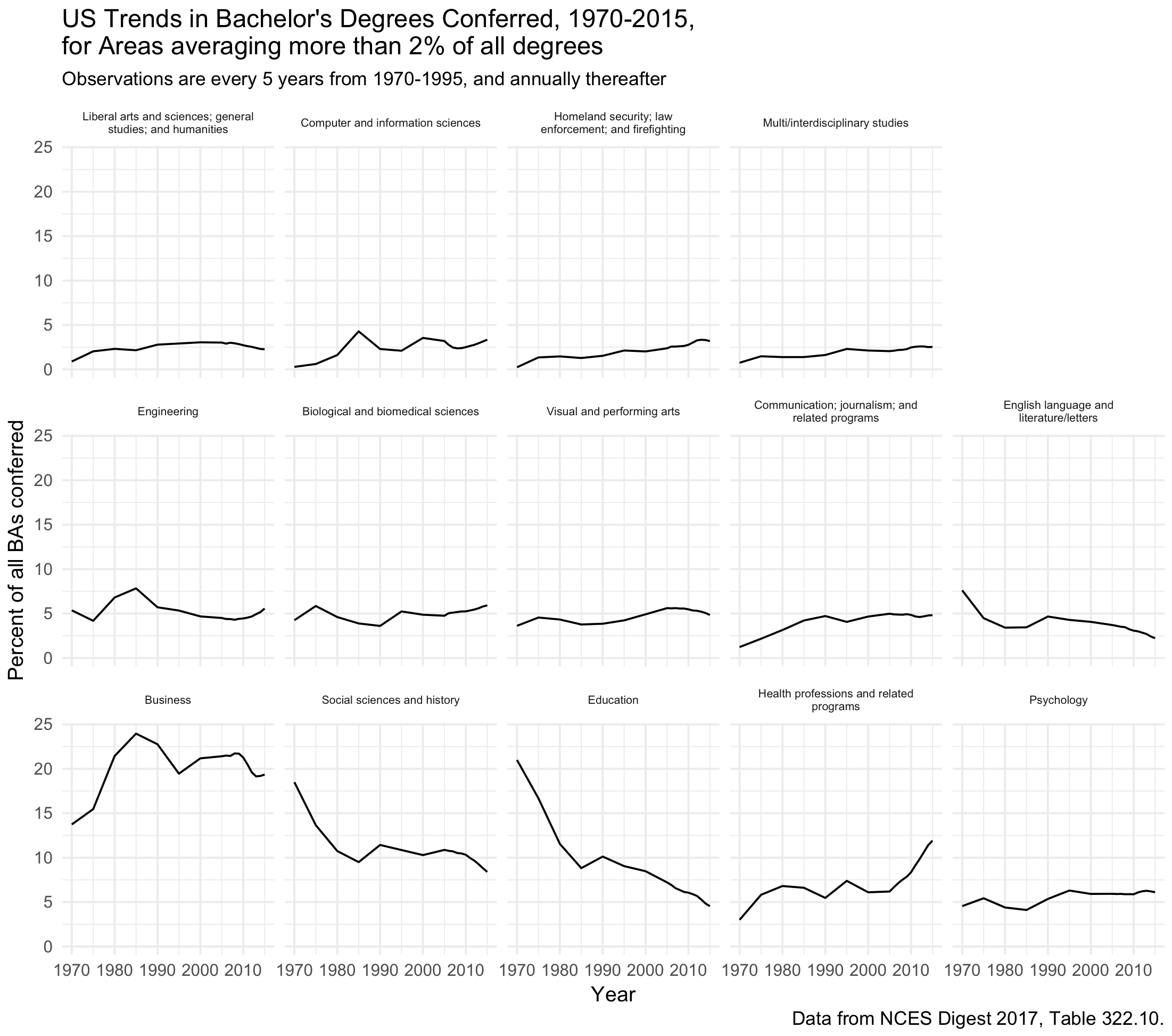
Facets ordered by setting as.table to FALSE. The bottom row is filled, but the ordering of the facets is not right, because the fill order now starts at the bottom left.
This fills the bottom row, but it breaks the high-to-low ordering that we’re trying to set with reorder(). We can get it back manually. First we create vars, which summarizes the areas of study by mean number of degrees awarded over the years. Separately, we great a vector, o, the same length as the subset of categories we’re going to display.
|
|
Here, instead of using reorder(), we recode the field_of_study variable on the fly, reordering its factor levels to reflect the desired panel order. We keep as.table = FALSE. The field_of_study categories then appear in the order we want.
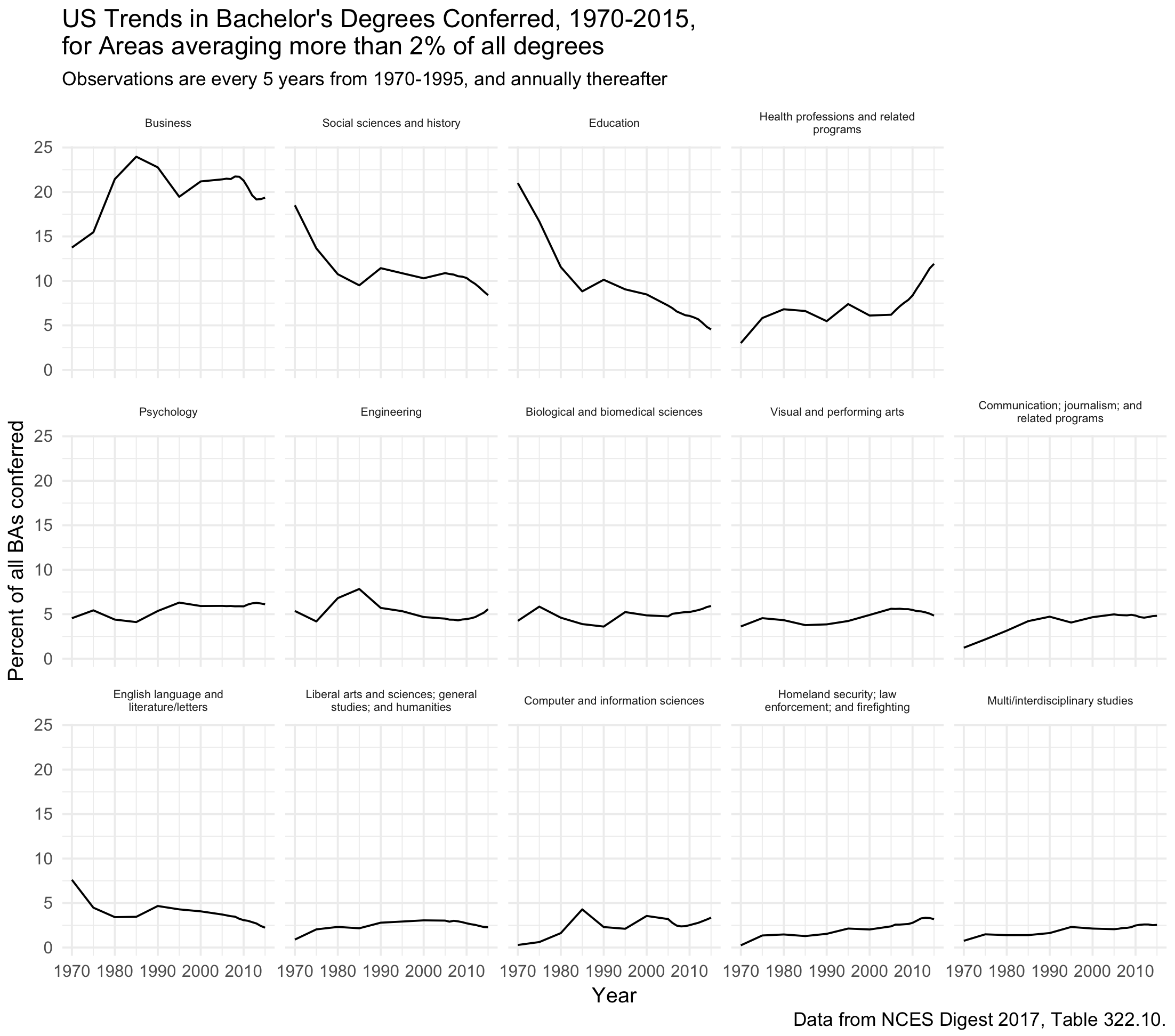
Keeping as.table set to FALSE, we manually re-order the field of study variable to re-establish the order.
We can do the same again for the fields with less than two percent of all degrees on average:
|
|
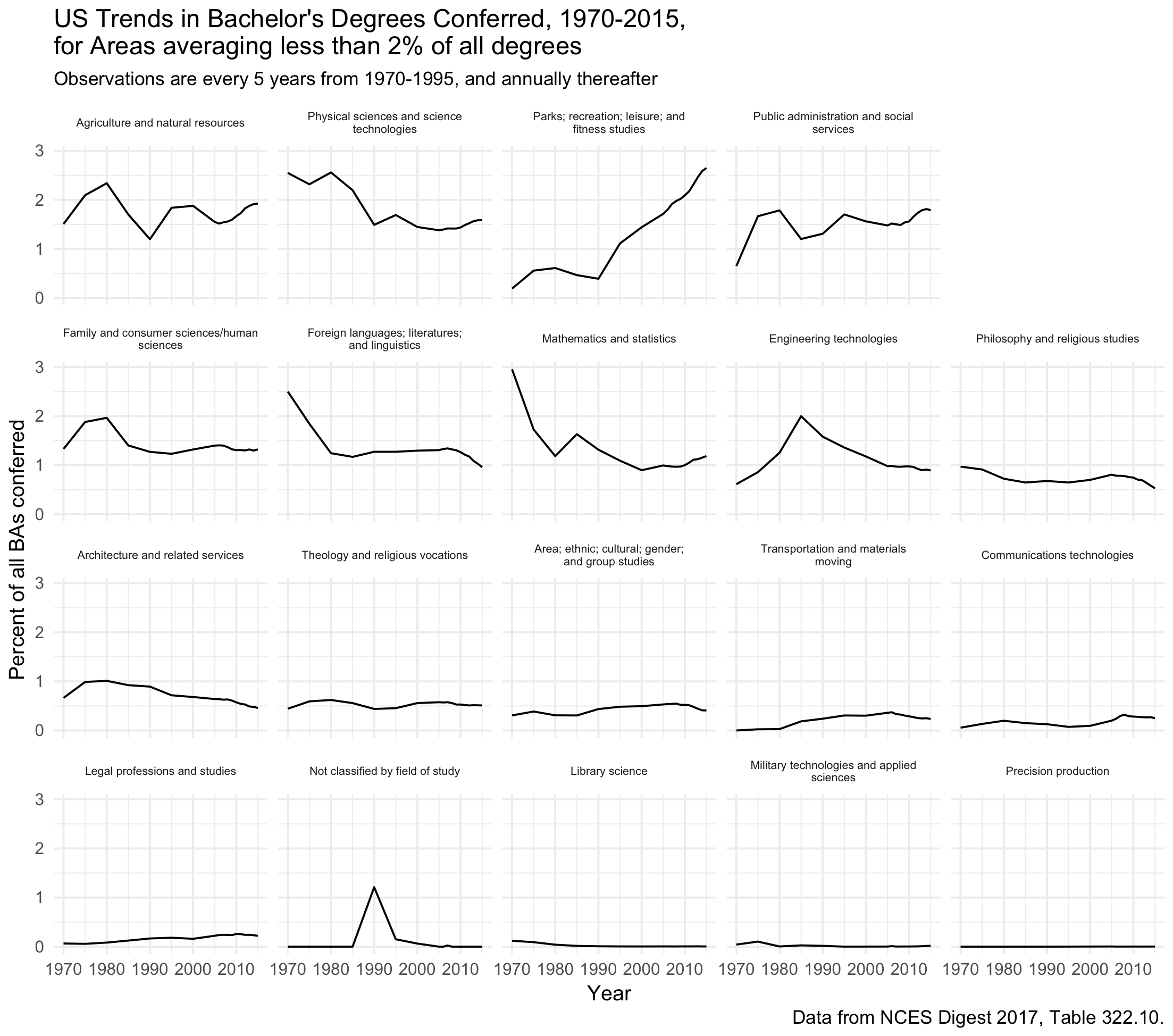
Same again for degrees with <2% of BAs.
Because we have a different number of categories, we need to manually reorder the variable again. This isn’t an ideal solution. What we really want is a way to automatically figure out how many facets we have, and then fill them from the bottom in the order we desire. I’m not sure this is easily doable.