Baby Name Animation
I was playing around with the gganimate package this morning and thought I’d make a little animation showing a favorite finding about the distribution of baby names in the United States. This is the fact—I think first noticed by Laura Wattenberg, of the Baby Name Voyager—that there has been a sharp, relatively recent rise in boys’ names ending in the letter ’n’, at the expense of names with ’e’, ’l’, and ‘y’ endings.
Our goal is to animate a bar chart showing this distribution as a bar chart with one bar for each letter, which we’ll draw once for each year from 1880 to 2017 and then smoothly stitch them together with gganimate’s tools.
Here’s the code in full, using the babynames dataset, which can be installed from CRAN.
|
|
The babynames data looks like this:
|
|
We’re going to create a plot object, p. We take the data and subset it to boys’ names, then calculate a table of end-letter frequencies by year. Finally, we add the instructions for the plot.
|
|
The first bit of code finds the last letter of every name in babynames using stringr’s str_sub() function. Then we count the number of ending letters and calculate a proportion, which we then rank. From there we hand things over to ggplot to draw a column chart. With gganimate you draw and polish the plot as normal—here just a column chart using geom_col()—and then add the animation instructions using transition_states() and ease_aes(). The only other trick is the use of the placeholder macro '{closest_state}' in the labs() call, where we specify the subtitle. This is what gives us the year counter.
With the plot object ready to go, we call animate() to save it to a file.
|
|
And here’s the result:
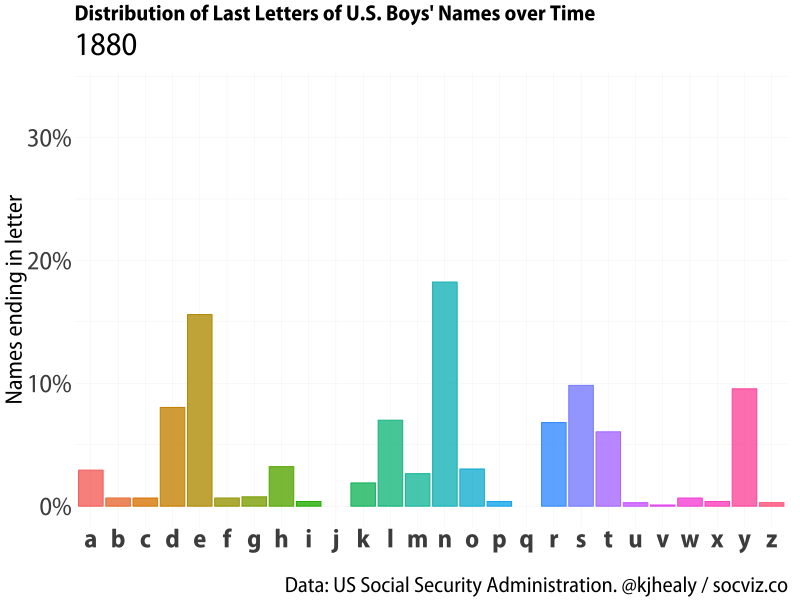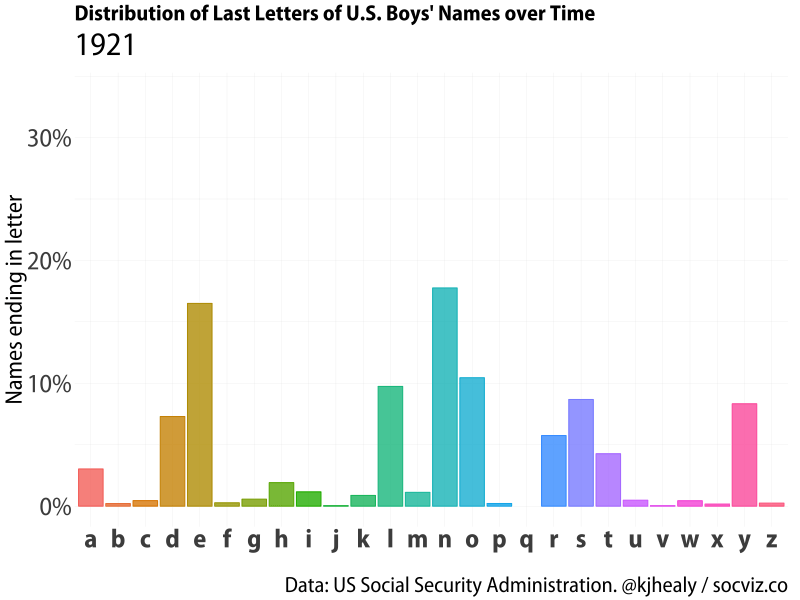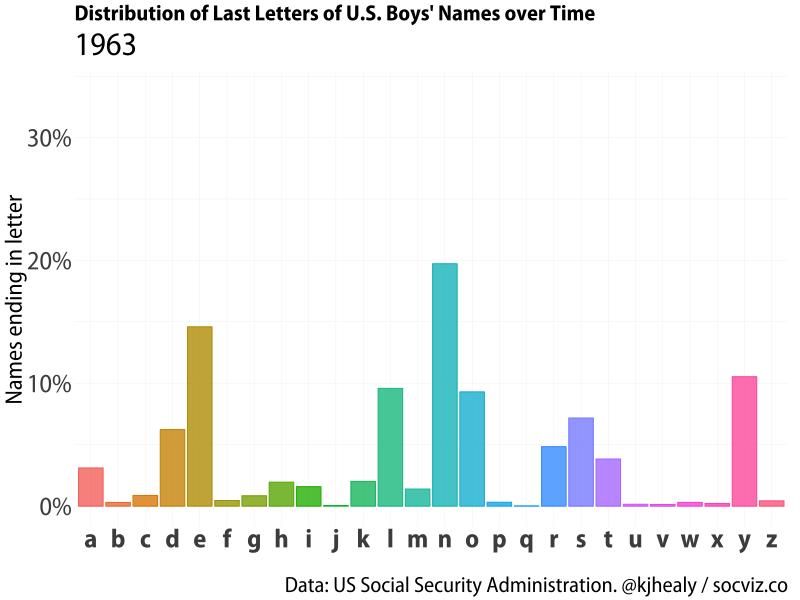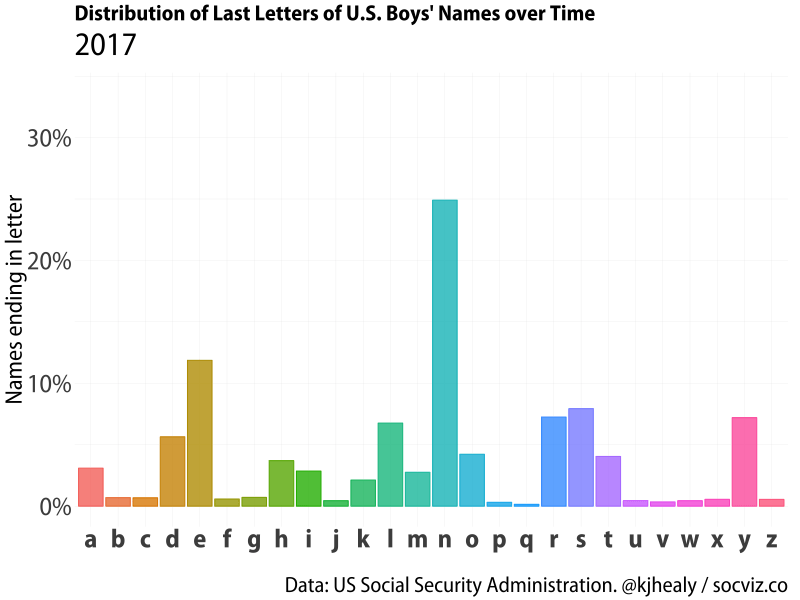
Animated distribution of end-letter names for boys.
By switching the filter from "M" to "F" we can do the same for girls’ names:
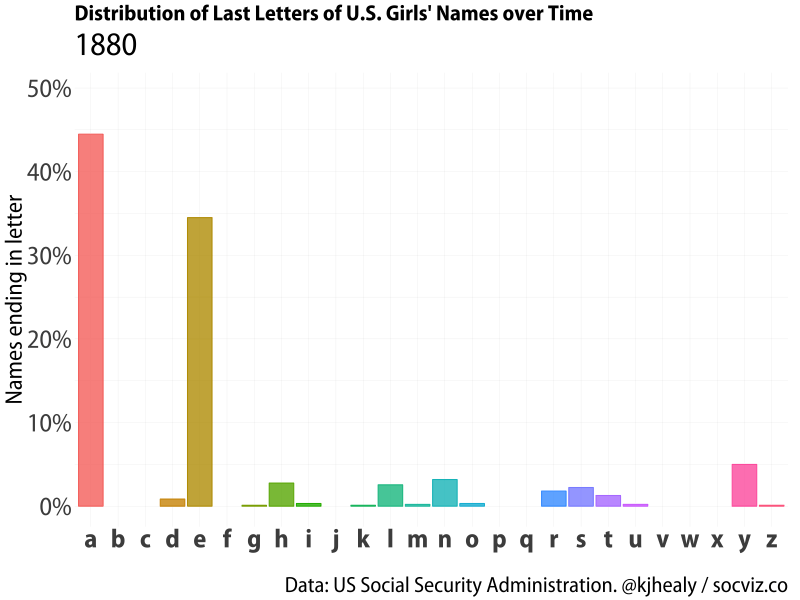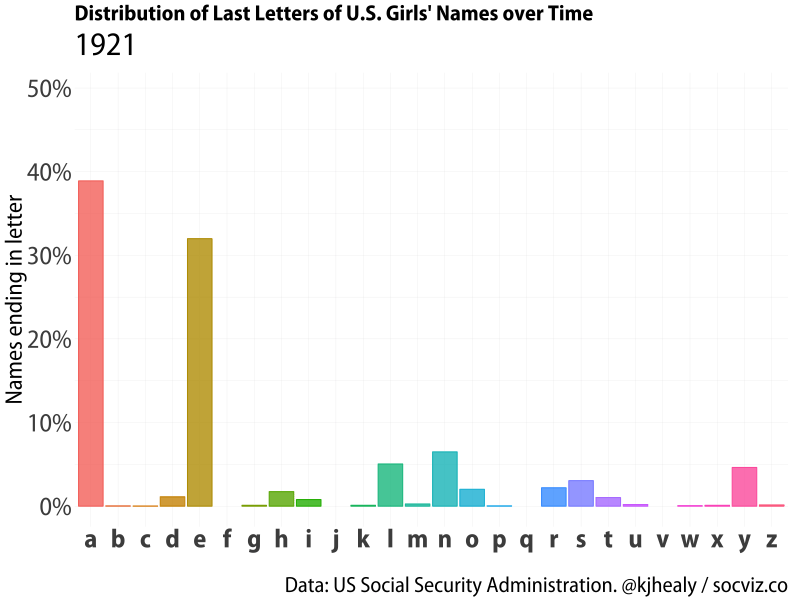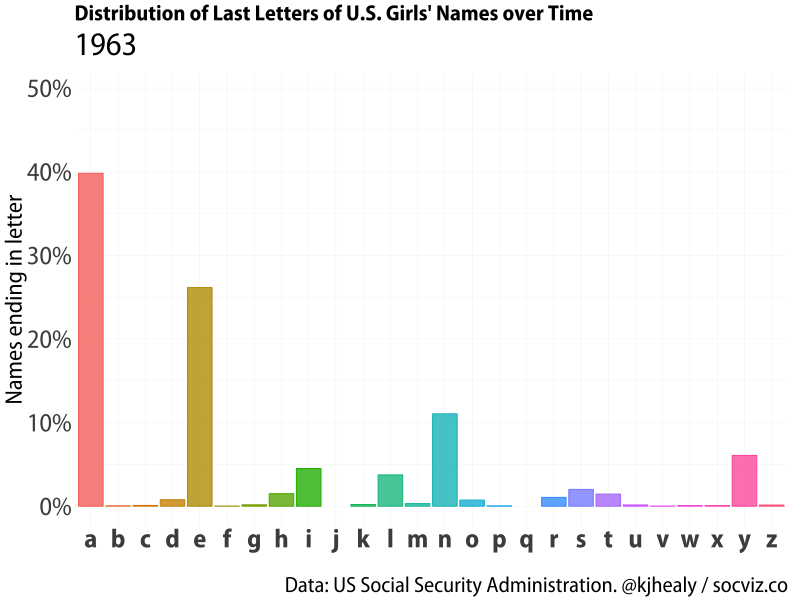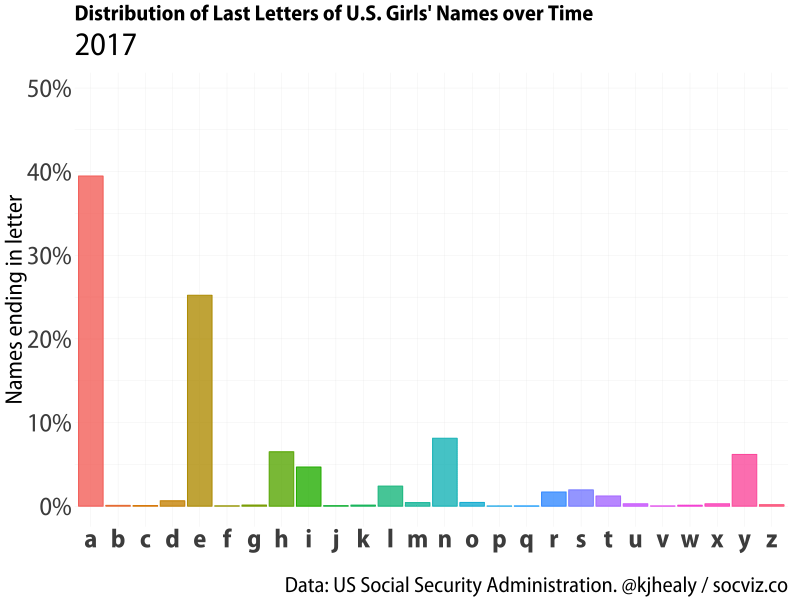
Animated distribution of end-letter names for girls.
Girls’ names show a very different distribution, with ‘a’ and ’e’ endings very common (perhaps unsurprisingly given the legacy of Latinate names), but there’s still substantial variation in how popular ‘a’ endings are over time. The dominance of ‘a’ and ’e’ is interesting, because girl names show more heterogeneity overall, with parents being more willing to experiment with the names of their daughters rather then their sons.