Departmental and Specialty Affinities net of Reputation
The two-sided quality of the connection between departments and specialties invites us to find ways of visualizing them both at the same time. But the large number of departments and specialties makes it tricky to generate interpretable pictures. There is a large family of methods designed to map multidimensional data onto just a couple of dimensions. Here I’ll take one of the more straightforward ways of doing this and apply it to the 2006 data.
Principal Components Analysis tries to reduce high-dimensional data to a few orthogonal dimensions, while preserving as much information about the data as possible. It can be tempting to talk about the results from PCA and similar approaches as revealing the true underlying structure in the data—and indeed sometimes, with related methods, that is in fact the goal. But here it’s best just to treat it as an exploratory approach, one that suggests interpretations which we might or might not find plausible, based on the substantive knowledge or theory that we have about the domain we are dealing with. This matters because the method is guaranteed to produce “underlying” components or factors courtesy the mechanics of the calculations it makes. Whether they’re meaningful or not is a separate question.
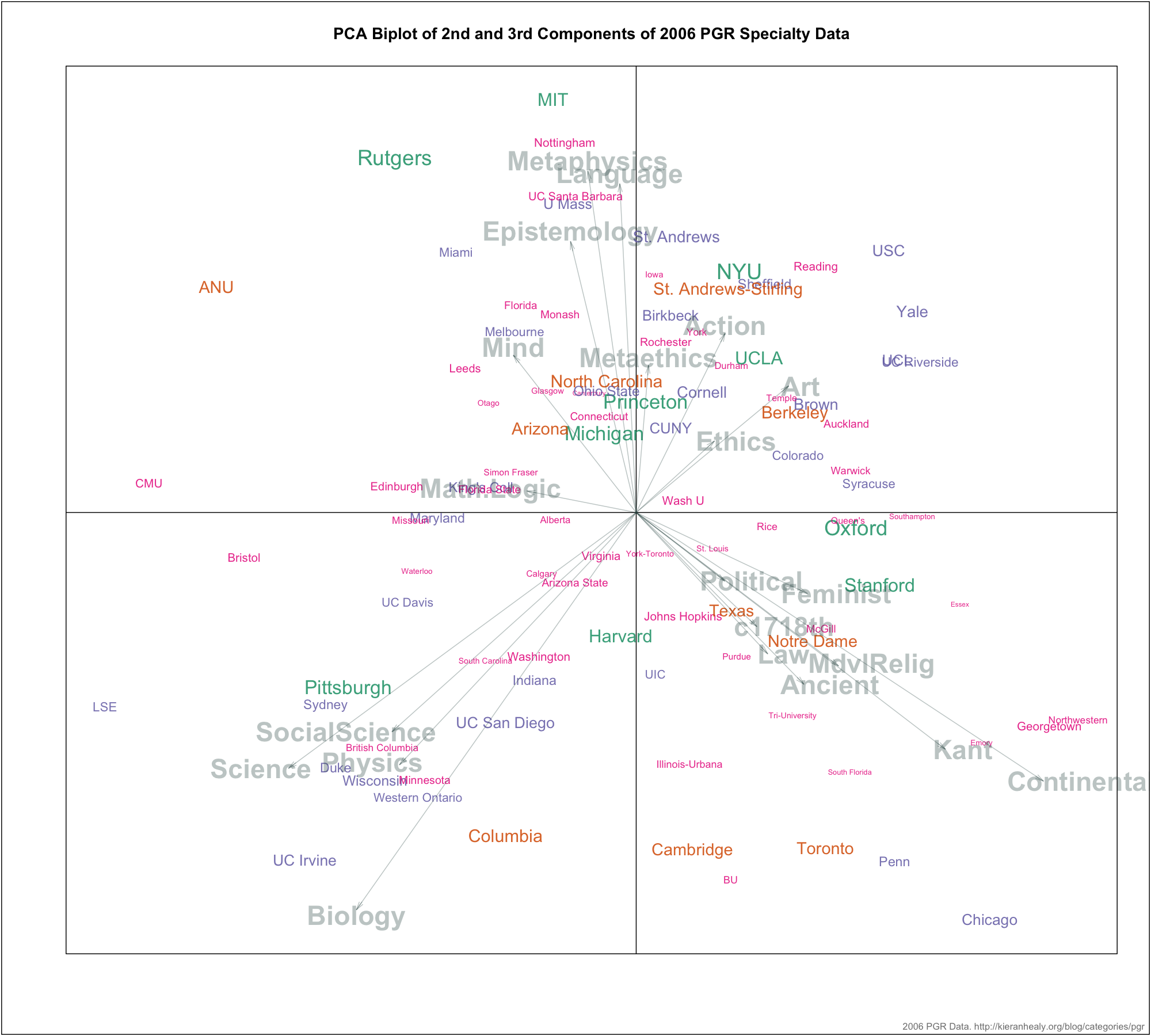
What I do here is run a PCA on the matrix of departments and their 2006 specialty-area scores—that’s 99 departments and 21 areas. I did combine just a few of the specialty areas that initial analysis showed always ended up right on top of each other (so there’s a Math/Logic/Decision Theory group, a Medieval/Religion group, a 17th and 18th century group, and a 19th and 20th century Continental group.) When we run the PCA we get a series of component scores, arranged in order of how much variation they “explain”. We can use these to define two-dimensional spaces. Then we can create a PCA biplot, which shows both departments and specialty areas at the same time. Here is the biplot based on the second and third principal components.
(Again the larger PNG or PDF versions are better to look at.)
How to intepret this? First, the specialty areas are represented in light gray text and each is associated with a vector pointing out from the origin of the figure. Departments are shown with their name colored and scaled based on which of five rank groups they belong to. (The bands are Top 10, 11-20, 21-50, and 51-99.) Specialty areas close to each other in the figure tend to be associated with one another. The same is true of department-to-department proximity and specialty-to-department proximity. For the specialty areas, the longer its vector, the more information from it is responsible for structuring the components. To see the department or specialty most different from a given one, draw a line from it through the origin and out the same distance on the other side. If a specialty area is close to a department, that doesn’t necessarily mean that specialism is the most important thing that department is known for. Rather it’s what distinguishes that department from others in this component space. Look at the location of the top-ranked departments, for example—it’s not that Oxford in 2006 wasn’t very good in Metaphysics or Language. In fact, it’s excellent in those areas. But what distinguishes it from, e.g., NYU or MIT is that it also has strength in Religion and Medieval philosophy, so gets pulled over into the lower-right quadrant.
You might be (you should be) wondering why I use the second and third components and not the first and second, given that by definition the first component will capture the most variance relative to the others. The reason is that the first component generated by the PCA is in effect something very close to the overall PGR ranking itself, and so using that more or less recreates the rank order of departments along one axis, with the specialty areas fanning out around it on the other. (Here is what that looks like, if you’re interested.) This is to be expected, as a dominant fact about the specialty rankings is the way they are collectively associated with the overall ranking. If we set aside the first component, we can think of the second and third components as representing relationships between departments and subfields net of reputation or status. So, amongst other things, the biplot lets us see whether and how top-ranked departments are distributed around this space of specialties, which specialties tend to be associated with one another even if they do not make equal contributions to overall status, and which departments are like one another, in some sense, even if they are not close together in overall rank. Again, while it shouldn’t be taken as a revelation about the structure of the field, as a bit of visualization I think it’s a useful heuristic device for thinking about how both departments and subfields differ from and resemble one another.