Outliers
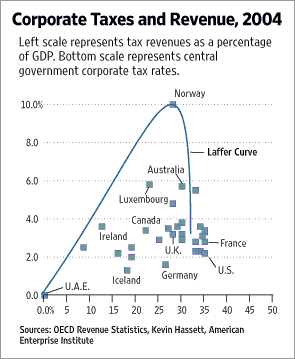
By now you’ve probably all seen this ridiculous graphic from todays’ WSJ, which purports to show that the Laffer curve is somehow related to the data points on the figure. Brad DeLong, Kevin Drum, Matt Yglesias, Mark Thoma and Max Sawicky have all rightly had a good old laugh at it, because it’s spectacularly dishonest and stupid. I just want to make a point about so-called outlying cases, like Norway.
In discussion threads about this kind of thing, you’ll find people saying stuff like, “I want to see a line showing x z or z”, or “I want to know what happens when you …”, and very often they’ll add “excluding outliers like Norway from the analysis.” Now, it’s true that in this plot Norway is very unlike the other countries. It’s also true that if you run regressions with data like this and don’t look at any plots while you do it then you will probably be misled by your coefficients, because some observations (like Norway) may have too much leverage or influence in the calculations. In this sense it’s important to take “outliers” into consideration.
But when your data set consists of just 18 or 25 advanced industrial democracies and your goal is to assess the empirical support for some alleged economic law, then you should be careful about tossing around the concept of “outlier.” In an important sense, Norway isn’t an outlier at all. It’s a real country, with a government and an economy and everything. Clearly they are doing something up there in the fjords to push the observed value up to the top of the graph. Maybe you don’t know what that is, but you shouldn’t just label it an outlying case and throw it away, at least not without re-specifying the scope of your question.
Dropping outlying observations in regressions used to be standard practice and is still pretty common. In his post on the topic, Max estimates a regression with the data, and he throws out “those annoying communist outliers at the top,” Norway and Luxembourg first (mostly to throw a bone to his opponents, I think). But as he notes, if you include them there’s no significant linear relationship between the corporate tax rate and and corporate revenue as a percentage of GDP. And this is the substantive issue. Cross-national data—especially when confined to OECD countries—often show surprisingly weak or non-existent evidence of supposedly strong theoretical trade-offs. That’s in part because there are often some annoying countries (like Norway or wherever) that cheerfully occupy the wrong place on the scatterplot, thereby making trouble for your perfectly nice generalization. Of course you can reasonably say something like “In the liberal democracies …” or “Excluding the corporatist countries …” or “Leaving aside the goddamn Scandinavians who have messed everything up again …” These days you can also use methods which incorporate information from all cases, but are resistant to letting one or two bits of data mess up your estimates. But what you really shouldn’t do—especially when the cases are in other respects quite similar, such as all being functioning, rich capitalist democracies—is label entire countries as “outliers” in order to remove them from your analysis, and then pretend that this has made them disappear from the face of the earth, too.